
Java stream性能比较
环境
- Ubuntu 22.04
- IntelliJ IDEA 2022.1.3
- JDK 17
- CPU:8核
➜ ~ cat /proc/cpuinfo | egrep -ie 'physical id|cpu cores'
physical id : 0
cpu cores : 1
physical id : 2
cpu cores : 1
physical id : 4
cpu cores : 1
physical id : 6
cpu cores : 1
physical id : 8
cpu cores : 1
physical id : 10
cpu cores : 1
physical id : 12
cpu cores : 1
physical id : 14
cpu cores : 1
目标
文本通过实际测试,从以下几个维度比较Java stream的性能:
- stream VS. parallelStream
- 分步 VS. 总体,分步指的是每次操作都转换为List,下个操作前再转换为stream,而总体指的是全部操作之后再转换为List。显然,总体的性能会好于分步的性能
- 不同数据量对性能的影响
准备
新建maven项目 test0317 。
打开 pom.xml 文件,添加如下内容:
junit junit 4.13.2 test 在 src/test/java/com.example.test0317 目录下创建package package1 ,并创建类 Test0317 :
package com.example.test0317.package1;import org.junit.Test;import java.util.List;
import java.util.stream.Stream;public class Test0317 {private List list1 = null;private long size = 10000000;private long start = 0;private long end = 0;private long time = 0;
}
测试
测试1(stream,10000000,分步)
@Testpublic void test1() {System.out.println("\n****** test1: stream, " + size + ", step by step ******");for (int i = 0; i < 3; i++) {list1 = Stream.generate(Math::random).limit(size).toList();start = System.currentTimeMillis();list1 = list1.stream().map(e -> e + 1).toList();list1 = list1.stream().map(e -> e * 2).toList();list1 = list1.stream().sorted().toList();end = System.currentTimeMillis();time = end - start;System.out.println("time = " + time);}}
运行结果如下:
****** test1: stream, 10000000, step by step ******
time = 6062
time = 5931
time = 6917
测试2(parallelStream,10000000,分步)
@Testpublic void test2() {System.out.println("\n****** test2: parallelStream, " + size + ", step by step ******");for (int i = 0; i < 3; i++) {list1 = Stream.generate(Math::random).limit(10000000).toList();start = System.currentTimeMillis();list1 = list1.parallelStream().map(e -> e + 1).toList();list1 = list1.parallelStream().map(e -> e * 2).toList();list1 = list1.parallelStream().sorted().toList();end = System.currentTimeMillis();time = end - start;System.out.println("time = " + time);}}
运行结果如下:
****** test2: parallelStream, 10000000, step by step ******
time = 2038
time = 1822
time = 2000
测试3(stream,10000000,总体)
@Testpublic void test3() {System.out.println("\n****** test3: stream, " + size + ", whole ******");for (int i = 0; i < 3; i++) {list1 = Stream.generate(Math::random).limit(10000000).toList();start = System.currentTimeMillis();list1 = list1.stream().map(e -> e + 1).map(e -> e * 2).sorted().toList();end = System.currentTimeMillis();time = end - start;System.out.println("time = " + time);}}
运行结果如下:
****** test3: stream, 10000000, whole ******
time = 6118
time = 5774
time = 6310
测试4(parallelStream,10000000,总体)
@Testpublic void test4() {System.out.println("\n****** test4: parallelStream, " + size + ", whole ******");for (int i = 0; i < 3; i++) {list1 = Stream.generate(Math::random).limit(10000000).toList();start = System.currentTimeMillis();list1 = list1.parallelStream().map(e -> e + 1).map(e -> e * 2).sorted().toList();end = System.currentTimeMillis();time = end - start;System.out.println("time = " + time);}}
运行结果如下:
****** test4: parallelStream, 10000000, whole ******
time = 1771
time = 1873
time = 2011
测试5(stream,20000000,分步)
运行结果如下:
****** test1: stream, 20000000, step by step ******
time = 12870
time = 12642
time = 12425
测试6(parallelStream,20000000,分步)
运行结果如下:
****** test2: parallelStream, 20000000, step by step ******
time = 4216
time = 4247
time = 4420
测试7(stream,20000000,总体)
运行结果如下:
****** test3: stream, 20000000, whole ******
time = 12199
time = 12136
time = 12088
测试8(parallelStream,20000000,总体)
运行结果如下:
****** test4: parallelStream, 20000000, whole ******
time = 3526
time = 3796
time = 4105
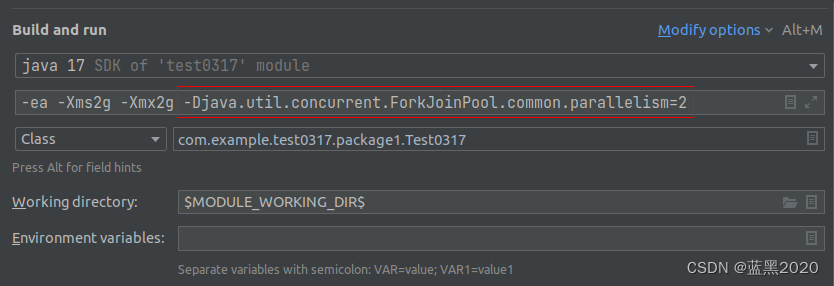
上面的测试中,因为CPU是8核,所以parallelStream最多使用8个线程,而下面的测试是指定使用2线程,方法为在JVM的启动选项(VM options)里设置 -Djava.util.concurrent.ForkJoinPool.common.parallelism=2 ,如下图所示:
测试9(2线程,parallelStream,10000000,分步)
运行结果如下:
****** test2: parallelStream, 10000000, step by step ******
time = 3446
time = 3246
time = 3523
测试10(2线程,parallelStream,10000000,总体)
运行结果如下:
****** test4: parallelStream, 10000000, whole ******
time = 3173
time = 3136
time = 3259
测试11(2线程,parallelStream,20000000,分步)
运行结果如下:
****** test2: parallelStream, 20000000, step by step ******
time = 7246
time = 7830
time = 7613
测试12(2线程,parallelStream,20000000,总体)
运行结果如下:
****** test4: parallelStream, 20000000, whole ******
time = 7292
time = 7438
time = 7109
总结
测试结果总结如下:
| stream VS. parallelStream | stepwise VS. whole | 元素个数 | 平均时间(秒) | 速度提升 | |
|---|---|---|---|---|---|
| 测试1 | stream | stepwise | 10000000 | 6.3 | baseline |
| 测试2 | parallelStream | stepwise | 10000000 | 2.0 | 3.15 |
| 测试3 | stream | whole | 10000000 | 6.1 | 1.03 |
| 测试4 | parallelStream | whole | 10000000 | 1.9 | 3.32 |
总结:在8核,10000000个元素的情况下,parallelStream相比stream性能提升很大,而总体相比分步只是略有性能提升。
如果把10000000个元素换为20000000个元素,测试结果如下:
| stream VS. parallelStream | stepwise VS. whole | 元素个数 | 平均时间(秒) | 速度提升 | |
|---|---|---|---|---|---|
| 测试5 | stream | stepwise | 20000000 | 12.6 | baseline |
| 测试6 | parallelStream | stepwise | 20000000 | 4.3 | 2.93 |
| 测试7 | stream | whole | 20000000 | 12.1 | 1.04 |
| 测试8 | parallelStream | whole | 20000000 | 3.8 | 3.32 |
可见,如果元素个数加倍,则对于每个测试结果,运行时间也都几乎加倍,符合线性增长。
总结:在8核,20000000个元素的情况下,parallelStream相比stream性能提升很大,而总体相比分步只是略有性能提升。
另外,若换成2线程,其性能显然在单线程和8线程之间。测试结果如下:
| stream VS. parallelStream | stepwise VS. whole | 元素个数 | 平均时间(秒) | 速度提升 | |
|---|---|---|---|---|---|
| 测试9 | parallelStream | stepwise | 10000000 | 3.3 | 1.91 |
| 测试10 | parallelStream | whole | 10000000 | 3.1 | 2.03 |
| 测试11 | parallelStream | stepwise | 20000000 | 7.6 | 1.66 |
| 测试12 | parallelStream | whole | 20000000 | 7.3 | 1.73 |
可见,2线程相比单线程,性能提升接近于2倍,但是达不到2倍,这是因为创建和切换线程需要消耗一定的时间和资源,同理,拆分及合并数据也需要消耗一定的时间和资源。
总结:在2线程,10000000或20000000个元素的情况下,parallelStream相比stream的性能提升接近于2倍,而总体相比分步只是略有性能提升。
最后多说一句:在数据量很大(本例中达到千万级别)时,parallelStream相比stream而言,性能有非常大的提升。但是若数据量不大,比如我测试了10000,则parallelStream相比stream,性能不但没有提升,甚至变得更差了,原因前面已经提到了。
不过话说回来,即使parallelStream比起stream性能变差,但因为数据量小,所以消耗的时间总量就少,比如说假设从10毫秒变成15毫秒,虽然多了50%的时间消耗,但是因为绝对值很小,所以问题不大。
从这个角度看来,还是应该尽量用parallelStream来取代stream。
当然,本例只是一个非常简单的模型,在一些复杂的情况下,比如有线程安全的问题,就要考虑应该用stream还是parallelStream。