
小米新一代Kaldi解读:新型自动语音识别 模型Zipformer诞生之路 小米语音识别开源方案 小米的智能语音识别功能
机器之心专栏
作者:新一代 Kaldi 团队
近日,小米集团新一代 Kaldi 团队关于语音识别声学模型的论文《Zipformer: A faster and better encoder for automatic speech recognition》被 ICLR 2024 接收为 Oral (Top 1.2%)。

论文链接:https://arxiv.org/pdf/2310.11230.pdf代码链接:https://github.com/k2-fsa/icefall/tree/master/egs/librispeech/ASR/zipformer

团队介绍
新一代 Kaldi 团队是由 Kaldi 之父、IEEE fellow、小米集团首席语音科学家 Daniel Povey 领衔的团队,专注于开源语音基础引擎研发,从神经网络声学编码器、损失函数、优化器和解码器等各方面重构语音技术链路,旨在提高智能语音任务的准确率和效率。
目前,新一代 Kaldi 项目主要由四个子项目构成:核心算法库 k2、通用语音数据处理工具包 Lhotse、解决方案集合 Icefall 以及服务端引擎 Sherpa,方便开发者轻松训练、部署自己的智能语音模型。
新一代 kaidi 项目:https://github.com/k2-fsa

论文解读
摘要
Zipformer[1] 作为一个新型的自动语音识别 (ASR) 模型,相比较于 Conformer[2]、Squeezeformer[3]、E-Branchformer[4] 等主流 ASR 模型,Zipformer 具有效果更好、计算更快、更省内存等优点。Zipformer 在 LibriSpeech、Aishell-1 和 WenetSpeech 等常用的 ASR 数据集上都取得了当前最好的实验结果。
Zipformer 的具体创新点,主要包括:
Downsampled encoder structure,降采样到不同的帧率,学习不同粒度的时域信息Zipformer block,更深的 block 结构,通过复用注意力权重提高效率BiasNorm,允许保留一定的长度信息Swoosh 激活函数,比 Swish 效果更好ScaledAdam 优化器,根据参数大小放缩更新量,保持不同参数相对变化一致,并显式学习参数大小,比 Adam 收敛更快、效果更好Balancer 和 Whitener,限制激活值,稳定训练
方法
1. Downsampled encoder structure
图 1 展示了 Zipformer 总体框架图,由一个 Conv-Embed 模块和多个 encoder stack 组成。不同于 Conformer 只在一个固定的帧率 25Hz 操作,Zipformer 采用了一个类似于 U-Net 的结构,在不同帧率上学习不同时间分辨率的时域表征。

首先,Conv-Embed 将输入的 100Hz 的声学特征下采样为 50 Hz 的特征序列;然后,由 6 个连续的 encoder stack 分别在 50Hz、25Hz、12.5Hz、6.25Hz、12.5Hz 和 25Hz 的采样率下进行时域建模。除了第一个 stack 外,其他的 stack 都采用了降采样的结构。在 stack 与 stack 之间,特征序列的采样率保持在 50Hz。不同的 stack 的 embedding 维度不同,中间stack 的 embedding 维度更大。每个 stack 的输出通过截断或者补零的操作,来对齐下一个 stack 的维度。Zipformer 最终输出的维度,取决于 embedding 维度最大的 stack。
对于降采样的 encoder stack,成对出现的 Downsample 和 Upsample 模块负责将特征长度对称地放缩。我们采用几乎最简单的方法实现 Downsample 和 Upsample 模块。例如,当降采样率为 2 时,Downsample 学习两个标量权重,用来将相邻的两帧加权求和了;Upsample 则只是简单地将每一帧复制为两帧。最后,通过一个 Bypass 模块,以一种可学习的方式结合 stack 的输入和输出。
2. Zipformer block
Conformer block 由四个模块组成:feed-forward、Multi-Head Self-Attention (MHSA)、convolution、feed-forward。MHSA 模块通过两个步骤学习全局时域信息:基于内积计算注意力权重,以及利用算好的注意力权重汇聚不同帧的信息。然而,MHSA 模块通常占据了大量的计算,因为以上两步操作的计算复杂度都是平方级别于序列长度的。因此,我们将 MHSA 模块根据这两个步骤分解为两个独立的模块:Multi-Head Attention Weight (MHAW)和Self-Attention (SA)。这样一来,我们可以通过在一个 block 里面使用一个 MHAW 模块和两个 SA 模块,以高效的方式实现两次注意力建模。此外,我们还提出了一个新的模块 Non-Linear Attention (NLA) ,充分利用已经算好的注意力权重,进行全局时域信息学习。

图 2 展示了 Zipformer block 的结构图,其深度大约是 Conformer block 的两倍。核心的思想是通过复用注意力权重来节省计算和内存。具体而言,block 输入先被送到 MHAW 模块计算注意力权重,并分享给 NLA 模块和两个 SA 模块使用。同时,block 输入也被送到 feed-forward 模块,后面接着 NLA 模块。接着是两个连续的模块组,每组包含 SA、convolution 和 feed-forward。最后,由一个 BiasNorm 模块来将 block 输出进行 normalize。除了普通的加法残差连接,每个 Zipformer block 还使用了两个 Bypass 模型,用于结合 block 输入和中间模块的输出,分别位于 block 的中间和尾部。
值得注意的是,我们并没有像常规的 Transformer 模型一样,对每个模块都使用 normalization layer 去周期性地调整激活值的范围,这得益于我们使用的 ScaledAdam 优化器可以为各个模型自动学习参数的 scale。
Non-Linear Attention


Bypass

3. BiasNorm

4. Swoosh 激活函数


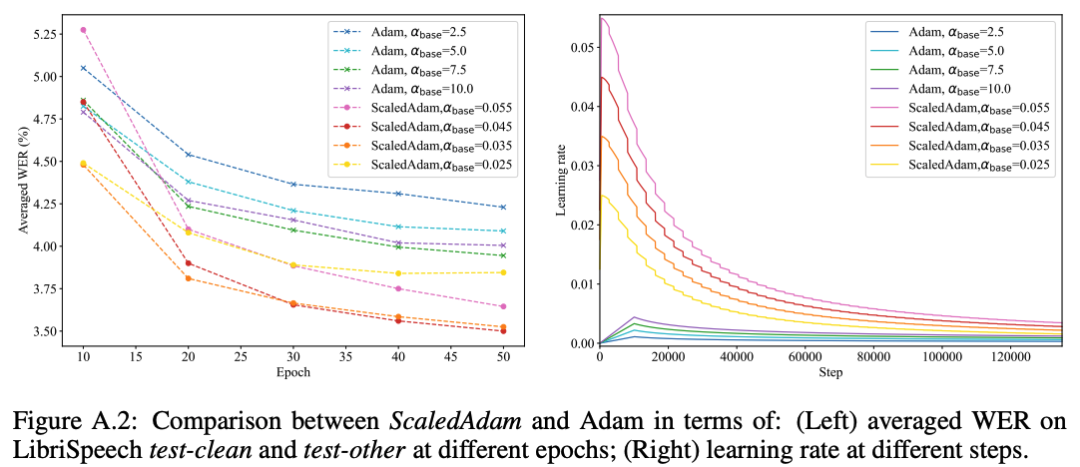
5. ScaledAdam

Scaling update

Learning parameter scale

Eden schedule

Efficient implementation

6. 激活值限制


1. 实验设置
Architecture variants
我们构建了三个不同参数规模的 Zipformer 模型:small (Zipformer-S), medium (Zipformer-M),large (Zipformer-L)。对于 Zipformer 的 6 个 stack,注意力头的数量为 {4,4,4,8,4,4},卷积核大小为 {31,31,15,15,15,31}。对于每个注意力头,query/key 维度为 32,value 维度为 12。我们通过调节 encoder embedding dim,层的数量,feed-forward hidden dim 来得到不同参数规模的模型:

数据集
我们在三个常用的数据集上进行实验:1)Librispeech[8],1000 小时英文数据;2)Aishell-1[9],170 小时中文;3)WenetSpeech[10],10000+ 小时中文数据。
实现细节
我们通过 Speed perturb 对数据进行三倍增广,使用 Pruned transducer[11] 作为 loss 训练模型,解码方法为 modified-beam-search[12](每帧最多吐一个字,beam size=4)。
默认情况下,我们所有的 Zipformer 模型是在 32GB NVIDIA Tesla V100 GPU 上训练。对于 LibriSpeech 数据集,Zipformer-M 和 Zipformer-L 在 4 个 GPU 上训练了 50 epoch,Zipformer-S 在 2 个 GPU 上训练了 50 个 epoch;对于 Aishell-1 数据集,所有 Zipformer 模型都在 2 个 GPU 上训练了 56 epoch;对于 WenetSpeech 数据集,所有 Zipformer 模型都在 4 个 GPU 上训练了 14 epoch。
2. 与 SOTA 模型比较
LibriSpeech
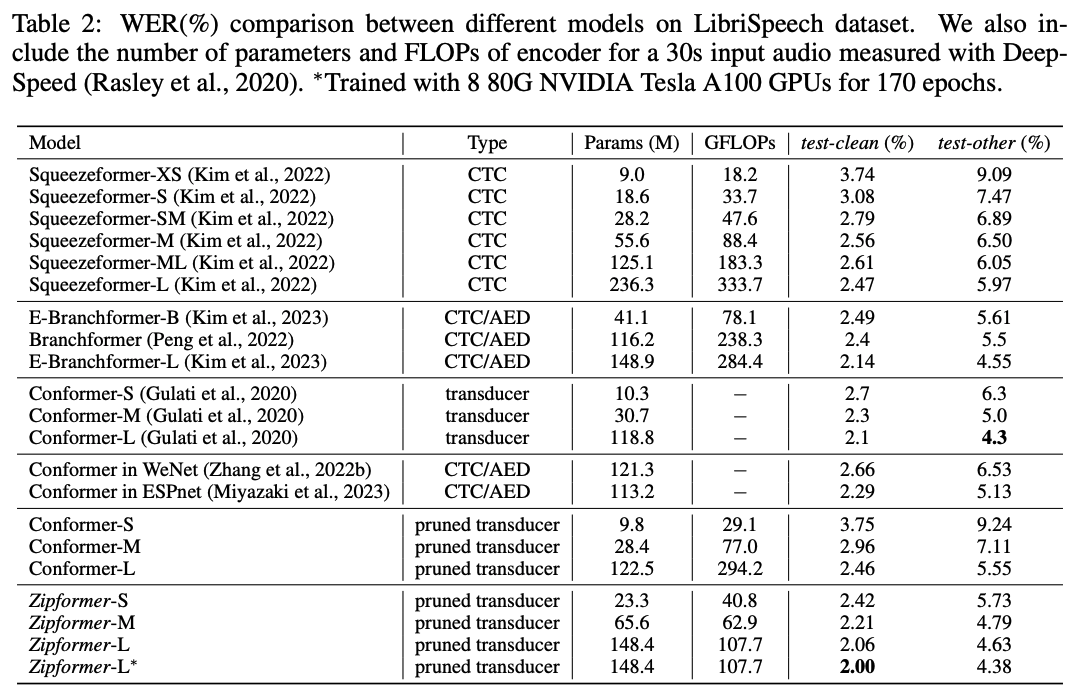
表 2 展示了 Zipformer 和其他 SOTA 模型在 LibriSpeech 数据集上的结果。对于 Conformer,我们还列出了我们复现的结果以及其他框架复现的结果。值得注意的是,这些结果和 Conformer 原文仍然存在一定的差距。Zipformer-S 取得了比所有的 Squeezeformer 模型更低的 WER,而参数量和 FLOPs 都更少。Zipformer-L的性能显著超过 Squeezeformer-L,Branchformer 和 我们复现的 Conformer,而 FLOPs 却节省了 50% 以上。值得注意的是,当我们在 8 个 80G NVIDIA Tesla A100 GPU 上训练 170 epoch,Zipformer-L 取得了 2.00%/4.38% 的 WER,这是我们了解到的迄今为止第一个和 Conformer 原文结果相当的模型。
我们还比较了 Zipformer 和其他 SOTA 模型的计算效率和内存使用。图 5 展示了不同 encoder 在单个 NVIDIA Tesla V100 GPU 上推理 30 秒长的语音 batch 所需的平均计算时间和峰值内存使用量,batch size 设置为 30,确保所有的模型都不会 OOM。总的来说,与其他的 SOTA 模型比较,Zipformer 在性能和效率上取得了明显更好的 trade-off。尤其是 Zipformer-L,计算速度和内存使用显著优于其他类似参数规模的模型。
此外,我们在论文附录中也展示了 Zipformer 在 CTC 和 CTC/AED 系统中的性能,同样超过了 SOTA 模型。CTC/AED 的代码在 https://github.com/k2-fsa/icefall/pull/1389。

Aishell-1
表 3 展示了不同模型在 Aishell-1 数据集的结果。相比较于 ESPnet 框架[13] 实现的 Conformer,Zipformer-S 性能更好,参数更少。增大参数规模后,Zipformer-M 和 Zipformer-L 都超过了其他所有的模型。

WenetSpeech
表 4 展示了不同模型在 WenetSpeech 数据集的结果。Zipformer-M 和 Zipformer-L 都在 Test-Net 和 Test-Meeting 测试集上超过了其他所有的模型。Zipformer-S 的效果超过了 ESPnet[13] 和 Wenet[14] 实现的 Conformer,参数量却只有它们的 1/3。
表 4:不同模型在 WenetSpeech 数据集的比较

目前,除了论文中展示的 LibriSpeech、Aishell-1 和 WenetSpeech 数据集外,我们的实验表明, Zipformer 在其它较大规模的 ASR 数据集上同样取得了新的 SOTA 结果。例如在 10000 h 的英文数据集 GigaSpeech[15] 上,不使用外部语言模型时,在 dev/test 测试集上,66M Zipformer-M 的 WER 为 10.25/10.38,288M Zipformer 的 WER 为 10.07/10.19。
3. 消融实验
我们在 LibriSpeech 数据集上进行了一系列消融实验,验证每一个模块的有效性,实验结果如表 5 所示。

Encoder structure
我们移除了 Zipformer 的 Downsampled encoder structure,类似于 Conformer 在 Conv-Embed 中使用 4 倍降采样,得到一个 12 层的模型,每层的 embedding dim 为 512。该模型在两个测试集上的 WER 都有所上升,这表明 Zipformer 中采用的 Downsampled encoder structure 并不会带来信息损失,反而以更少的参数达到更好的性能。
Block structure
由于每个 Zipfomer block 含有两倍于 Conformer block 的模块数量,我们将每个 Zipformer block 替换为两个 Conformer block,这导致了在 test-other 上的 WER 上升了 0.16%,并且带来更多的参数量,这体现了 Zipformer block 的结构优势。移除 NLA 或者 Bypass 模块都导致了性能下降。对于移除了 NLA 的模型,当我们移除注意力共享机制,这并没有带来性能提升,反而会带来更多的参数和计算量。我们认为在 Zipformer block 中两个注意力模块学习到的注意力权重具有高度一致性,共享注意力权重并不会有损模型性能。
Normalization layer
将 BiasNorm 替换为 LayerNorm 导致在 test-clean 和 test-other 两个测试集上 WER 分别上升了 0.08% 和 0.18%,这表明了 BiasNorm 相对于 LayerNorm 的优势,可以对输入向量保留一定程度的长度信息。
Activation function
当给 Zipformer 所有的模块都是用 SwooshR 激活函数的时候,test-clean 和 test-other 两个测试集上 WER 分别上升了 0.11% 和 0.42%,这表明给那些学习 “normally-off” 行为的模块使用 SwooshL 激活函数的优势。给所有的模块使用 Swish 激活函数导致了更严重的性能损失,这体现了 SwooshR 相对于 Swish 的优势。
Optimizer

Activation constraints
如表 6 所示,我们将 Balancer 移除掉后并不会带来明显的性能变化,但是没有对激活值的范围作限制会增大模型不收敛的风险,尤其是在使用混合精度训练的时候。移除掉 Whitener 导致了在 test-clean 和 test-other 两个测试集上分别下降了 0.04% 和 0.24%,这表明通过限制激活值的协方差矩阵特征值尽可能相同,有助于让提升模型性能。

结语
目前,Zipformer 已在小米产线数据上充分验证了其优越性能,有效提升识别准确率,降低服务器成本。Zipformer 相关技术,如 ScaledAdam 等,已被用于小米大模型训练。另外,我们的初步实验表明,Zipformer 在视觉模型上同样展示了有效性。
参考文献
[1] Zipformer: A faster and better encoder for automatic speech recognition (https://arxiv.org/pdf/2310.11230)
[2] Conformer: Convolution-augmented Transformer for Speech Recognition (https://arxiv.org/abs/2005.08100)
[3] Squeezeformer: An Efficient Transformer for Automatic Speech Recognition (https://arxiv.org/abs/2206.00888)
[4] E-Branchformer: Branchformer with Enhanced merging for speech recognition (https://arxiv.org/abs/2210.00077)
[5] Layer Normalization (https://arxiv.org/abs/1607.06450)
[6] Swish: a Self-Gated Activation Function (https://arxiv.org/abs/1710.05941v1)
[7] Adam: A Method for Stochastic Optimization (https://arxiv.org/abs/1412.6980)
[8] LibriSpeech: An ASR corpus based on public domain audio books (https://danielpovey.com/files/2015_icassp_librispeech.pdf)
[9] Aishell-1: An open-source mandarin speech corpus and a speech recognition baseline (https://arxiv.org/abs/1709.05522)
[10] WenetSpeech: A 10000+ Hours Multi-domain Mandarin Corpus for Speech Recognition (https://arxiv.org/abs/2110.03370)
[11] Pruned RNN-T for fast, memory-efficient ASR training (https://arxiv.org/abs/2206.13236)
[12] Fast and parallel decoding for transducer (https://arxiv.org/abs/2211.00484)
[13] ESPnet: https://github.com/espnet/espnet
[14] Wenet: https://github.com/wenet-e2e/wenet
[15] GigaSpeech: An Evolving, Multi-domain ASR Corpus with 10,000 Hours of Transcribed Audio (https://arxiv.org/abs/2106.06909)
上一篇:李佳琦一连翻车3次,对老粉翻脸不认人后,开始对沪圈跪舔....... 李佳琦面对粉丝的质疑时的回应 李佳琦言论“翻车”掉粉百万
下一篇:为何哪吒X卖不过元Plus和埃安Y?从产品到营销,3个拷问来聊聊 埃安y和哪吒x哪个值得买 哪吒x明年购买便宜吗