
大分辨率数据集切割
创始人
2025-05-30 10:19:16
0次
前言:对于航拍、遥感影像数据集而言,此类数据集包含较多目标,且目标相对较小,直接进行目标检测往往效果不佳,此时对大分辨率图像做切割就是一个不错选择,也扩充了数据量。
~~~本文的切割思路是先将xml文件转换为dota格式的txt文件,然后利用dota切割方法对图像进行切割,最后再将切割后的文件转换为yolo格式的txt文件~~~
1、xml文件转换为dota格式的txt文件
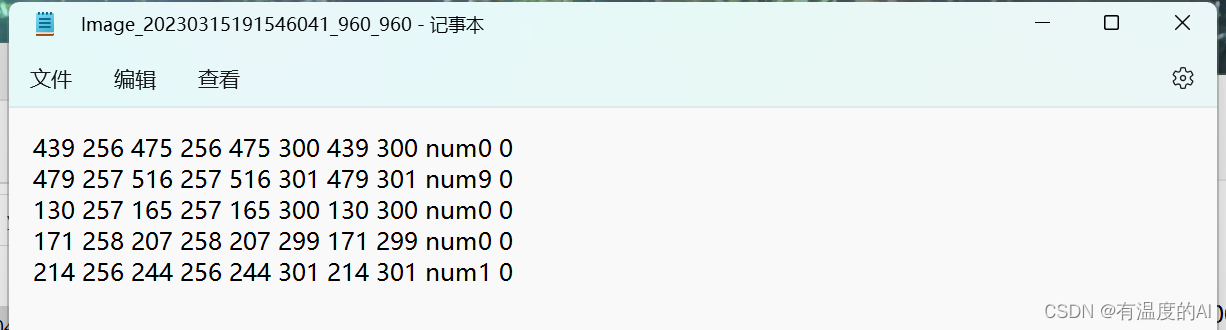
# VOC标注格式为左上角与右下角坐标
# 这个文件直接将标注框左上角与右下角坐标转换为四个角的坐标(顺时针)
import xml.etree.ElementTree as ET
import pickle
import os
import os.path
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test', 'val']
classes = ['num0', 'num1', 'num2', 'num3', 'num4', 'num5', 'num6', 'num7', 'num8', 'num9']def convert(size, box):dw = 1. / size[0]dh = 1. / size[1]x = (box[0] + box[1]) / 2.0y = (box[2] + box[3]) / 2.0w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn (x, y, w, h)
def convert_annotation(image_id):if os.path.isfile('datasets/mydata/Annotations/%s.xml' % (image_id)):in_file = open('datasets/mydata/Annotations/%s.xml' % (image_id))out_file = open('datasets/mydata/labels/%s.txt' % (image_id), 'w')tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):difficult = obj.find('difficult').textcls = obj.find('name').textif cls not in classes or int(difficult) == 1:continue# cls_id = classes.index(cls)xmlbox = obj.find('bndbox')# 注意dota数据格式四个角点的坐标是顺时针分布的x0 = int(float(xmlbox.find('xmin').text))y0 = int(float(xmlbox.find('ymin').text))x1 = int(float(xmlbox.find('xmax').text))y1 = int(float(xmlbox.find('ymin').text))x2 = int(float(xmlbox.find('xmax').text))y2 = int(float(xmlbox.find('ymax').text))x3 = int(float(xmlbox.find('xmin').text))y3 = int(float(xmlbox.find('ymax').text))out_file.write("{} {} {} {} {} {} {} {} {} {}\n".format(x0, y0, x1, y1, x2, y2, x3, y3, cls, difficult))
wd = getcwd()
print(wd)
for image_set in sets:if not os.path.exists('datasets/mydata/labels/'):os.makedirs('datasets/mydata/labels/')image_ids = open('datasets/mydata/%s.txt' % (image_set)).read().strip().split()list_file = open('datasets/mydata/%s.txt' % (image_set), 'w')for image_id in image_ids:list_file.write('datasets/mydata/images/%s.jpg\n' % (image_id))convert_annotation(image_id)list_file.close()#数据存放格式
#|——根目录
# |——datasets
# |——dota_images
# |——dota_labels
# |——yolo_labels
# |——mydata
# |——Annotations
# |——images
# |——labels
# test.txt
# train.txt
# val.txt 

2、图像切割
import cv2
import os# 图像宽不足裁剪宽度,填充至裁剪宽度
def fill_right(img, size_w):size = img.shape# 填充值为数据集均值img_fill_right = cv2.copyMakeBorder(img, 0, 0, 0, size_w - size[1],cv2.BORDER_CONSTANT, value = (107, 113, 115))return img_fill_right# 图像高不足裁剪高度,填充至裁剪高度
def fill_bottom(img, size_h):size = img.shapeimg_fill_bottom = cv2.copyMakeBorder(img, 0, size_h - size[0], 0, 0,cv2.BORDER_CONSTANT, value = (107, 113, 115))return img_fill_bottom# 图像宽高不足裁剪宽高度,填充至裁剪宽高度
def fill_right_bottom(img, size_w, size_h):size = img.shapeimg_fill_right_bottom = cv2.copyMakeBorder(img, 0, size_h - size[0], 0, size_w - size[1],cv2.BORDER_CONSTANT, value = (107, 113, 115))return img_fill_right_bottom# 图像切割
# img_floder 图像文件夹
# out_img_floder 图像切割输出文件夹
# size_w 切割图像宽
# size_h 切割图像高
# step 切割步长
# 不管输入图片是什么格式,切割出来的图片都为.bmp格式(可自行设置)
def image_split(img_floder, out_img_floder, size_w, size_h, step):img_list = os.listdir(img_floder)# print(img_list)count = 0for img_name in img_list:number = 0# 去除.png后缀name = img_name[:-4]img = cv2.imread(img_floder + "\\" + img_name)size = img.shape# 若图像宽高大于切割宽高if size[0] >= size_h and size[1] >= size_w:count = count + 1for h in range(0, size[0] - 1, step):start_h = hfor w in range(0, size[1] - 1, step):start_w = wend_h = start_h + size_hif end_h > size[0]:start_h = size[0] - size_hend_h = start_h + size_hend_w = start_w + size_wif end_w > size[1]:start_w = size[1] - size_wend_w = start_w + size_wcropped = img[start_h : end_h, start_w : end_w]# 用起始坐标来命名切割得到的图像,为的是方便后续标签数据抓取name_img = name + '_'+ str(start_h) +'_' + str(start_w)cv2.imwrite('{}/{}.bmp'.format(out_img_floder, name_img), cropped)number = number + 1# 若图像高大于切割高,但宽小于切割宽elif size[0] >= size_h and size[1] < size_w:print('图片{}需要在右面补齐'.format(name))count = count + 1img0 = fill_right(img, size_w)for h in range(0, size[0] - 1, step):start_h = hstart_w = 0end_h = start_h + size_hif end_h > size[0]:start_h = size[0] - size_hend_h = start_h + size_hend_w = start_w + size_wcropped = img0[start_h : end_h, start_w : end_w]name_img = name + '_' + str(start_h) + '_' + str(start_w)cv2.imwrite('{}/{}.bmp'.format(out_img_floder, name_img), cropped)number = number + 1# 若图像宽大于切割宽,但高小于切割高elif size[0] < size_h and size[1] >= size_w:count = count + 1print('图片{}需要在下面补齐'.format(name))img0 = fill_bottom(img, size_h)for w in range(0, size[1] - 1, step):start_h = 0start_w = wend_w = start_w + size_wif end_w > size[1]:start_w = size[1] - size_wend_w = start_w + size_wend_h = start_h + size_hcropped = img0[start_h : end_h, start_w : end_w]name_img = name + '_'+ str(start_h) +'_' + str(start_w)cv2.imwrite('{}/{}.bmp'.format(out_img_floder, name_img), cropped)number = number + 1# 若图像宽高小于切割宽高elif size[0] < size_h and size[1] < size_w:count = count + 1print('图片{}需要在下面和右面补齐'.format(name))img0 = fill_right_bottom(img, size_w, size_h)cropped = img0[0 : size_h, 0 : size_w]name_img = name + '_'+ '0' +'_' + '0'cv2.imwrite('{}/{}.bmp'.format(out_img_floder, name_img), cropped)number = number + 1print('{}.bmp切割成{}张.'.format(name,number))print('共完成{}张图片'.format(count))# txt切割
# out_img_floder 图像切割输出文件夹
# txt_floder txt文件夹
# out_txt_floder txt切割输出文件夹
# size_w 切割图像宽
# size_h 切割图像高
def txt_split(out_img_floder, txt_floder, out_txt_floder, size_h, size_w):img_list = os.listdir(out_img_floder)for img_name in img_list:# 去除.png后缀name = img_name[:-4]# 得到原图像(也即txt)索引 + 切割高 + 切割宽name_list = name.split('_')# 易报错之处,此处需要跟据图片的具体名称来改txt_name = name_list[0] + '_' + name_list[1]h = int(name_list[2])w = int(name_list[3])# txt_name = name_list[0]# h = int(name_list[1])# w = int(name_list[2])txtpath = txt_floder + "\\" + txt_name + '.txt'out_txt_path = out_txt_floder + "\\" + name + '.txt'f = open(out_txt_path, 'a')# 打开txt文件with open(txtpath, 'r') as f_in:lines = f_in.readlines()# 逐行读取for line in lines:splitline = line.split(' ')label = splitline[8]difficult = splitline[9]x1 = int(float(splitline[0]))y1 = int(float(splitline[1]))x2 = int(float(splitline[2]))y2 = int(float(splitline[3]))x3 = int(float(splitline[4]))y3 = int(float(splitline[5]))x4 = int(float(splitline[6]))y4 = int(float(splitline[7]))if w <= x1 <= w + size_w and w <= x2 <= w + size_w and \w <= x3 <= w + size_w and w <= x4 <= w + size_w and \h <= y1 <= h + size_h and h <= y2 <= h + size_h and \h <= y3 <= h + size_h and h <= y4 <= h + size_h:f.write('{} {} {} {} {} {} {} {} {} {}'.format(int(x1 - w),int(y1 - h), int(x2 - w), int(y2 - h), int(x3 - w),int(y3 - h), int(x4 - w), int(y4 - h),label, difficult))f.close()# print('{}.txt切割完成.'.format(name))print('txt切割完成')# 图像数据集文件夹
img_floder = r'D:\cnn\yolov5-6.10\datasets\mydata\images'
# 切割得到的图像数据集存放文件夹
out_img_floder = r'D:\cnn\yolov5-6.10\datasets\dota_images'
# txt数据集文件夹
txt_floder = r'D:\cnn\yolov5-6.10\datasets\mydata\labels'
# 切割后数据集的标签文件存放文件夹
out_txt_floder = r'D:\cnn\yolov5-6.10\datasets\dota_labels'
# 此为切割出来的图像宽
size_w = 640
# 此为切割出来的图像高
size_h = 640
# 切割步长,重叠度为size_w - step
step = 540image_split(img_floder, out_img_floder, size_w, size_h, step)
txt_split(out_img_floder, txt_floder, out_txt_floder, size_h, size_w)# 清除未包含标注框的图片和txt文件
txt_lists = os.listdir(out_txt_floder) # 读取输出的txt文件
j = 0
for txt_list in txt_lists:# print(txt_list)name = txt_list[:-4] # 去除.txt后缀# print(name)data = open(r'D:\cnn\yolov5-6.10\datasets\dota_labels\{}'.format(txt_list)).read()if len(data) == 0:j = j + 1# print("{}文件为空!".format(txt_list))# os.remove('D:\cnn\yolov5-6.10\datasets\dota_labels')path1 = r'D:\cnn\yolov5-6.10\datasets\dota_labels\{}'.format(txt_list)os.remove(path1) # 删除空的txt文件path2 = r'D:\cnn\yolov5-6.10\datasets\dota_images\{}'.format(name + '.bmp')os.remove(path2) # 删除对应的没有标注框的图片
print('共{}个txt文件为空'.format(j))#数据存放格式
#|——根目录
# |——datasets
# |——dota_images
# |——dota_labels
# |——yolo_labels
# |——mydata
# |——Annotations
# |——images
# |——labels
# test.txt
# train.txt
# val.txt 运行完后会在dota_images和dota_labels文件夹中生成切割后的图片和txt文件。
3、将dota格式的txt文件转换为yolo格式的txt文件
# 在网上找了很久没找到转化的代码,索性就自己写了一个import osclasses = ['num0', 'num1', 'num2', 'num3', 'num4', 'num5', 'num6', 'num7', 'num8', 'num9']
path = "D:\cnn\yolov5-6.10\datasets\dota_labels" # dota格式txt文件所在目录
yolo_label = 'D:\cnn\yolov5-6.10\datasets\yolo_labels' # yolo格式txt文件保存目录label_lists = os.listdir(path) # 得到文件夹下的所有文件名称
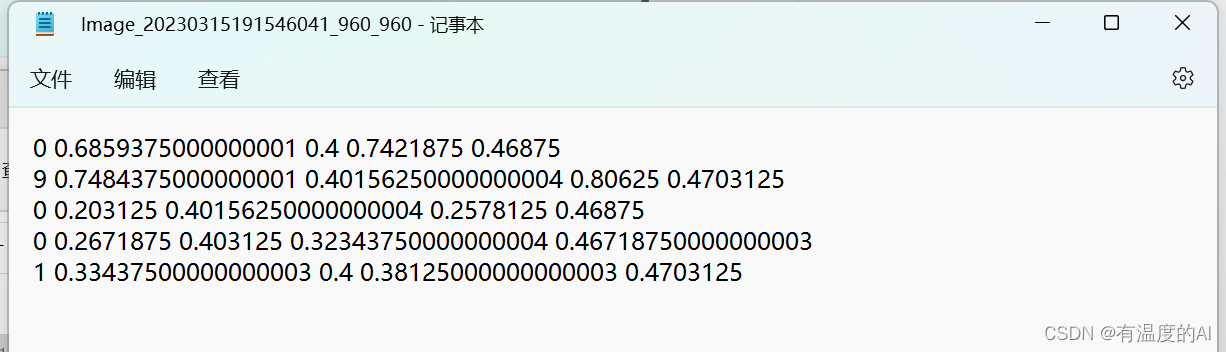
for label_list in label_lists: # 遍历文件夹out_txt_path = yolo_label + "\\" + label_list # 构造输出绝对路径,label_list为txt文件名称,即保证文件命名不变position = path + '\\' + label_list # 构造绝对路径,"\\",其中一个'\'为转义符# print(position)with open(position, 'r') as f: # 打开文件lines = f.readlines() # 逐行读取文件file = open(out_txt_path, 'w') # 写入nums = len(lines) # 总共有多少行for i in range(nums): # 遍历每一行values = lines[i]value = values.split(' ')# 因为dota格式四个角为顺时针,转为yolo格式需要取出其左上角和右下角xmin = float(value[0])ymin = float(value[1])xmax = float(value[4])ymax = float(value[5])cls = value[8]cls_id = classes.index(cls)d = 1. / 640 # 归一化处理,此处切割出来的图片宽高都是640file.write('{} {} {} {} {}\n'.format(cls_id, float(xmin * d), float(ymin * d), float(xmax * d), float(ymax * d)))tips:一定要记得归一化处理,因为yolo格式是要求归一化后的坐标!!!
至此,就得到了用于yolo训练的切割数据集!!!
跑程序的时候发现这种yolo格式不对(目前还不知道什么原因),继续往下看~~~
4、将yolo格式的txt文件转换为xml文件,此时可以用labelimg查看切割效果
import os
import glob
from PIL import Imageyolo_labels = r'D:\cnn\yolov5-6.10\datasets\yolo_labels' # yolo格式下的存放txt标注文件的文件夹
# 这里将图片和xml文件存放在一个文件夹中,方便后续使用labelimg查看
xml_labels = r'D:\cnn\yolov5-6.10\datasets\dota_images' # 转换后储存xml的文件夹地址
dota_images = r'D:\cnn\yolov5-6.10\datasets\dota_images' # 存放图片的文件夹labels = ['num0', 'num1', 'num2', 'num3', 'num4', 'num5', 'num6', 'num7', 'num8', 'num9']
src_img_dir = dota_images
src_txt_dir = yolo_labels
src_xml_dir = xml_labels # 转换后储存xml的文件夹地址img_lists = glob.glob(src_img_dir + '/*.bmp')
img_basenames = []
for item in img_lists:img_basenames.append(os.path.basename(item)) # os.path.basename返回path最后的文件名img_names = []
for item in img_basenames:temp1, temp2 = os.path.splitext(item) # os.path.splitext(“文件路径”) 分离文件名与扩展名img_names.append(temp1)total_num = len(img_names) # 统计当前总共要转换的图片标注数量
count = 0 # 技术变量
for img in img_names: # 这里的img是不加后缀的图片名称count += 1if count % 1000 == 0:print("当前转换进度{}/{}".format(count, total_num))im = Image.open((src_img_dir + '/' + img + '.bmp'))width, height = im.size# 打开yolo格式下的txt文件gt = open(src_txt_dir + '/' + img + '.txt').read().splitlines()if gt:# 将主干部分写入xml文件中xml_file = open((src_xml_dir + '/' + img + '.xml'), 'w')xml_file.write('\n')xml_file.write(' VOC2007 \n')xml_file.write(' ' + str(img) + '.bmp' + ' \n')xml_file.write(' \n')xml_file.write(' ' + str(width) + ' \n')xml_file.write(' ' + str(height) + ' \n')xml_file.write(' 3 \n')xml_file.write(' \n')# write the region of image on xml filefor img_each_label in gt:spt = img_each_label.split(' ') # 这里如果txt里面是以逗号‘,’隔开的,那么就改为spt = img_each_label.split(',')。xml_file.write(' \n')xml_file.write(' ')else:# 将主干部分写入xml文件中xml_file = open((src_xml_dir + '/' + img + '.xml'), 'w')xml_file.write('\n')xml_file.write(' VOC2007 \n')xml_file.write(' ' + str(img) + '.bmp' + ' \n')xml_file.write(' \n')xml_file.write(' ' + str(width) + ' \n')xml_file.write(' ' + str(height) + ' \n')xml_file.write(' 3 \n')xml_file.write(' \n')xml_file.write(' ')使用labelimg打开dota_images文件夹就可以查看切割后的效果啦!!!
5、 再将xml格式文件转换为txt格式文件
import xml.etree.ElementTree as ET
import pickle
import os
import os.path
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test', 'val']
classes = ['num0', 'num1', 'num2', 'num3', 'num4', 'num5', 'num6', 'num7', 'num8', 'num9']def convert(size, box):dw = 1. / size[0]dh = 1. / size[1]x = (box[0] + box[1]) / 2.0y = (box[2] + box[3]) / 2.0w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn (x, y, w, h)
def convert_annotation(image_id):if os.path.isfile('datasets/mydata/Annotations/%s.xml' % (image_id)):in_file = open('datasets/mydata/Annotations/%s.xml' % (image_id))out_file = open('datasets/mydata/labels/%s.txt' % (image_id), 'w')tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):difficult = obj.find('difficult').textcls = obj.find('name').textif cls not in classes or int(difficult) == 1:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:if not os.path.exists('datasets/mydata/labels/'):os.makedirs('datasets/mydata/labels/')image_ids = open('datasets/mydata/%s.txt' % (image_set)).read().strip().split()list_file = open('datasets/mydata/%s.txt' % (image_set), 'w')for image_id in image_ids:list_file.write('datasets/mydata/images/%s.jpg\n' % (image_id))convert_annotation(image_id)list_file.close()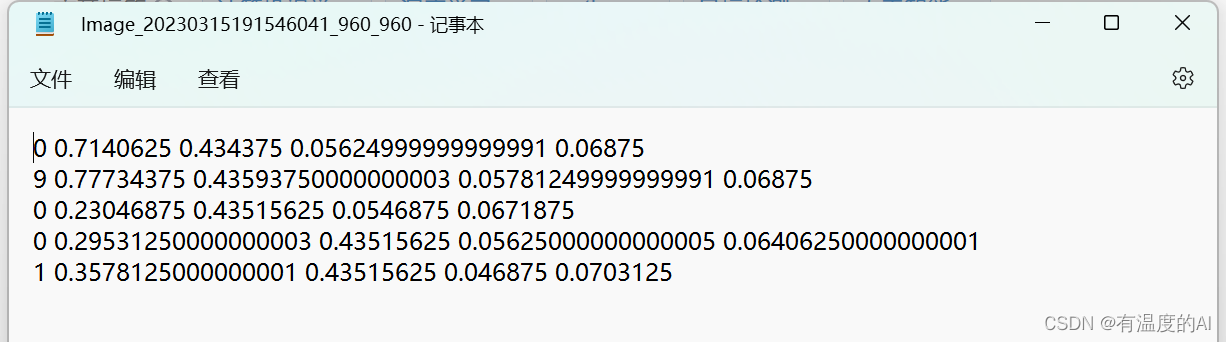
至此,就得到了用于yolo训练的切割数据集!!!
相关内容
热门资讯
走进小城看消费丨江西资溪:低碳...
夏日时节下午4点,江西省抚州市资溪县大觉山景区漂流终点依然热闹。来自南昌的游客余鑫漂流结束后没有...
【中原晨会0625】市场分析专...
来源:市场资讯 (来源:中原证券研究所) 本期重点研报目录 【中原策略】市场分析:电子半导体领涨 ...
南向资金连买4日!低费率+可月...
6月25日早盘,港股红利资产震荡整理。截至11时14分,港股红利低波ETF招商(520550)下跌0...
618成交破百万!紫荆花用一套...
一年一度的618年中大促,是消费市场的晴雨表,也是品牌间最激烈的角力场。当各大品牌在直播间里铆足了劲...
原创 黄...
2026年6月25日的国际金价已经从前期的5500美元高点跌到4200美元下方,累计跌幅超过22%,...
英伟达CEO:Vera Rub...
截至9:38,中证半导体材料设备主题指数(931743)涨2.36%创新高;权重股中,中微公司涨3....
再被催债16亿!“钢铁大王”戴...
澎湃新闻记者 贺梨萍 因“铁本事件”入狱五年的戴国芳重返钢铁行业,但他并没有完成从阶下囚再到“钢铁大...
周三原油价格下跌
随着美国和伊朗在和平谈判中取得进展,越来越多的油轮公开穿越霍尔木兹海峡,原油在战时的价格上涨已经蒸发...
这种蛋白是大脑衰老的开关
这种蛋白是大脑衰老的开关 清晨,假设一位五十岁左右的王女士发现自己常常把手机放在熟悉的抽屉里又找不到...
信通院牵头算力Token出海生...
盘面上,截至11:04,中证科创创业50指数(931643)涨1.68%,创历史新高;权重股中,芯原...
海外 774 亿营收背后:日本...
文 | 游戏价值论 6月23日,彭博社报道了腾讯正在围绕出售多家日本游戏工作室少数股权开展谈判,包...
餐饮“抢人”大战:把店开到公交...
作者 |餐饮老板内参 内参君 医院、公交站、演唱会…餐饮品牌,正在无孔不入 在北京儿童医院,肯德基...
快讯 | 外资扫货!陈翊庭:港...
港交所行政总裁陈翊庭在接受《中国证券报》专访时指出,国际资本对中国资产的看法已彻底扭转,布局中国市场...
2777.77元!A股“股王”...
25日早盘,昨天创下历史新高的A股“股王”联讯仪器,今天上午继续走强,盘中股价再度刷新历史新高。 截...
原创 今...
欧洲自己的媒体直接下结论,欧盟衰退躲不掉,内部分裂拦不住,现在就连欧洲顶尖工业巨头,都偷偷在用中国的...
黄仁勋股东大会放言:本轮AI基...
在当地时间6月24日的英伟达(NVDA.O)2026年度股东大会上,股东批准了该公司全部10名董事会...
国际油价大跌
新华社消息, 纽约原油期货主力合约价格24日盘中跌破每桶70美元,为伊朗战事爆发以来首次。 市场分析...
马云带队插秧,什么信号?
一场别开生面的“务农”,让外界看到了一个不一样的阿里巴巴。 近日,阿里巴巴合伙人、高德董事长刘振飞在...
全球最大产能,最高丰度达99....
本文转自【科技日报】; 6月23日,高丰度硼-10同位素技术暨产业化成果发布会在山东省东营市举办,全...
黄金大跳水!金饰克价年内暴跌近...
25日,现货黄金盘中震荡,截至发稿,报3985.070美元/盎司,跌0.17%。 当地时间24日,...