强化学习稀疏奖励问题(sparse reward)及解决方法
参考 《EasyRL》
1.稀疏奖励
通常在训练智能体时,我们希望每一步动作都有相应的奖励。但是某些情况下,智能体并不能立刻获得奖励,比如全局奖励的围棋,最终获胜会得到奖励,但是人们很难去设定中间每步的奖励,这会导致学习缓慢甚至无法进行学习的问题。
2.解决方法
2.1 设计奖励(reward shaping)
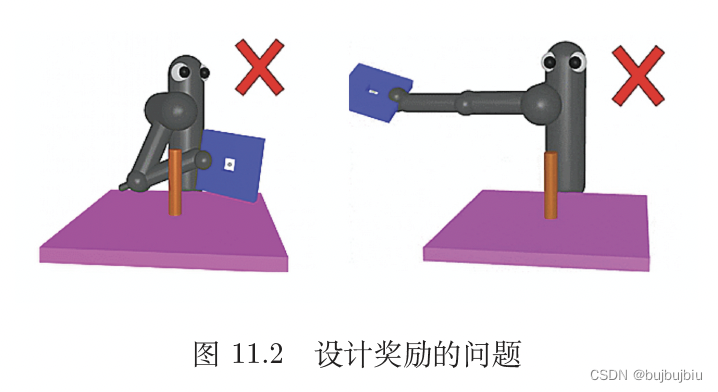
除了最终要学习到的目标外,可以额外添加一些奖励用于引导智能体。比如ViZDoom射击游戏,杀了敌人得到正奖励,被杀得到负奖励。探究人员设计了一些新奖励,来引导智能体做的更好,比如掉血就扣分,捡到补给包会加分,待在原地扣分,活着扣一个很小的分(否则智能体只想活着,躲避敌人)等方法。reward shaping技术需要领域知识(domain knowledge),不合理的设计奖励方式会让智能体学习到错误的方法。比如希望机器人将蓝色板子穿过柱子,通常会想到板子靠近柱子就加分,距离越近奖励越大,但是这样机器人可能会学习到用蓝色板子打柱子,而不是从上面穿过。因此设计奖励的效果与领域知识有关,需要调整。
2.2 好奇心(curiosity)
自己加入并且一般看起来有用的奖励,比如给智能体加上好奇心,称为好奇心驱动的奖励(curiosity driven reward),在好奇心驱动的技术里,我们会加入一个新的奖励函数:内在好奇心模型(intrinsic curiosity module,ICM)。ICM模块需要3个输入:状态s1,动作a1,状态s2,根据输入输出另外一个奖励rc(1)。对于智能体,在与环境交互时,不仅希望原始奖励r越大,也希望好奇心奖励rc越大。如何设计好奇心模块?用一个网络,接受输入a(t),s(t),输出,也就是用这个网络去预测
,看预测值与真实s(t+1)的相似度,越不相似奖励越高。也就是说,好奇心奖励的意义在于:未来的状态越难被预测,得到的奖励就越大,这样方便探索未知的世界。
好奇心模块的设置有一个问题:某些状态很难被预测到并不代表它就是好的,就是需要被尝试的。比如某些游戏中,会突然出现树叶飘动,这是无法预测的,智能体会一直看着树叶飘动。因此智能体仅有好奇心是不够的,还需要知道什么事情是真正重要的。
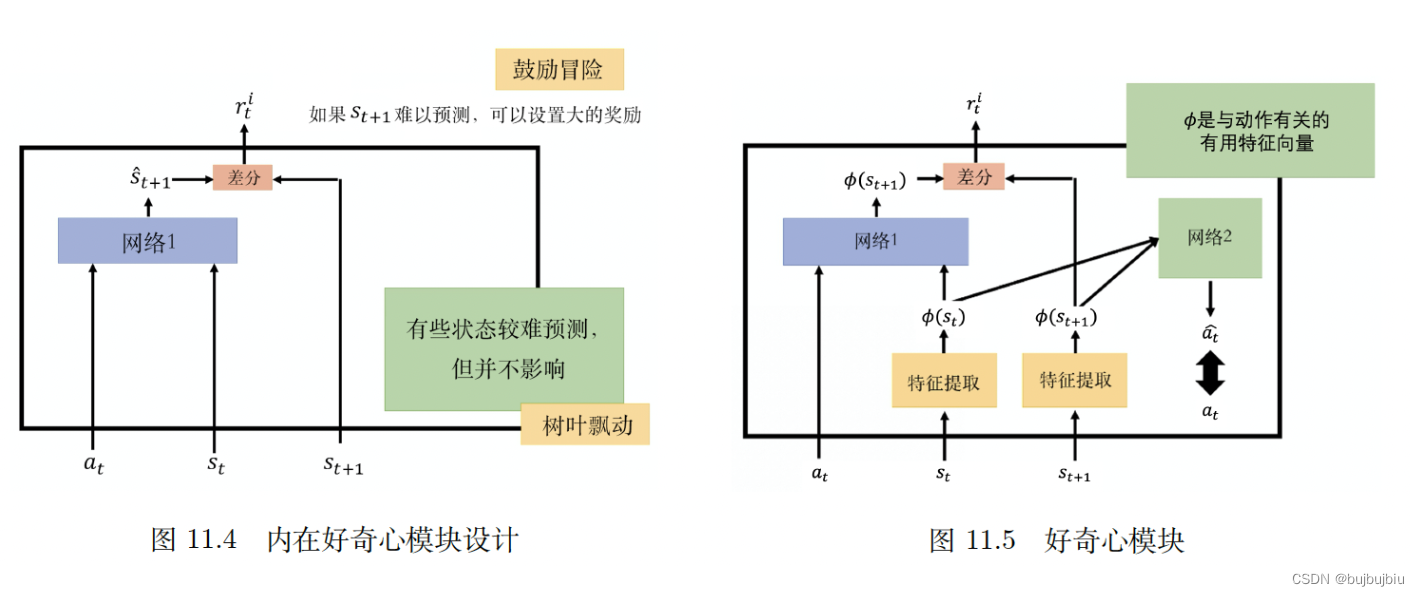
为了知道什么事情是重要的,避免不必要的冒险,要加上另外一个模块,学习特征提取器(feature extractor) 。如图所示,黄色格子是特征提取器,输入一个状态s(t),输出一个特征向量表示这个状态,特征提取器可以把无意义的东西过滤掉。那么内在好奇心网络1实际上输入的是a(t)和特征向量,输出下一状态特征向量
。如何学习特征提取器,通过网络2学习,网络2输入
和
,输出预测动作
,这个动作与真实动作越接近越好。网络2是用提取后的特征向量预测动作,因此像风吹草动这种与智能体动作无关的信息就会被过滤掉。
2.3课程学习(curriculum learning)
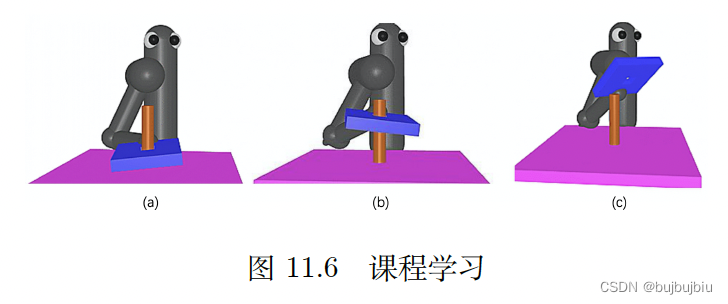
课程学习不只是强化学习中的概念,深度学习,机器学习等领域也会经常用到。课程学习也就是为智能体学习做规划,用于训练的数据通常是有顺序的,从易到难。比如教人学英语,直接学长句很困难,要先单词,然后是短语,最后学习长句。比如在训练循环神经网络时,已经有多篇文献证明,先看短序列,再看长序列,可以学习的更好。对于前面蓝色板子穿过柱子的任务,一开始设置板子已经在柱子上(a),智能体就能容易学到只需要按压板子即可。然后板子放高一点智能体可能会学习到拿起板子(b)。在学会按压和拿起后,在(c)场景下,板子先离柱子远一点,当智能体把板子拿到柱子上面时,就会知道要按压下去。
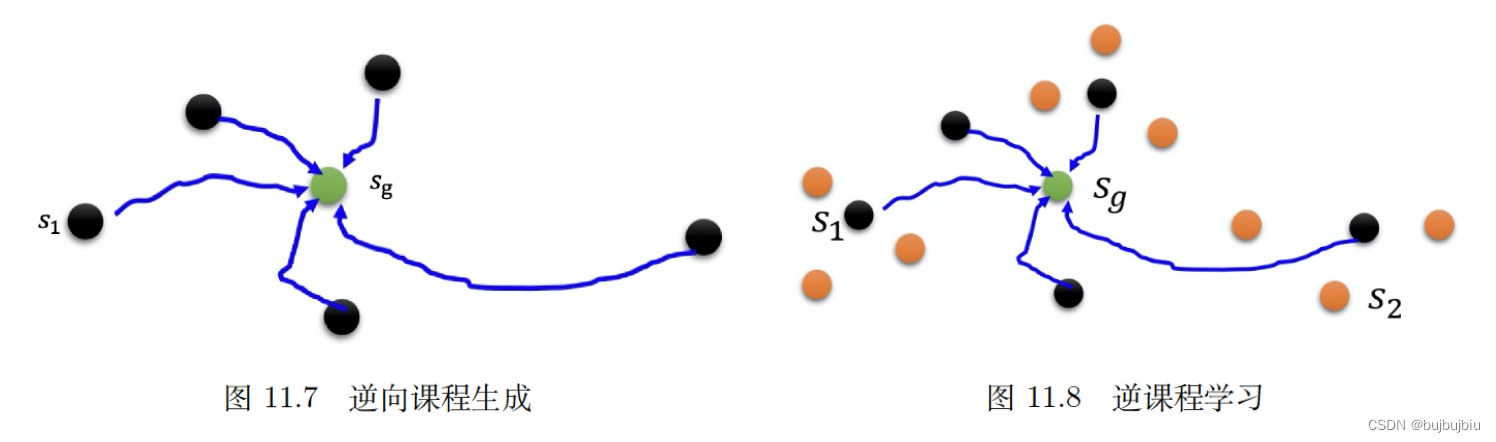
课程学习需要人为设计课程。有一个通用的方法是:逆向课程生成(reverse curriculum generation)。假设一开始有一个状态s(g),黄金状态(gold state),也就是最后最理想的结果。比如训练机械臂抓东西,抓到东西就是黄金状态。假设和s(g)很近的状态称为s1,至于s1需要根据任务来设计怎样从s(g)采样到s1,然后智能体从s1开始与环境交互,看能不能够到达黄金状态s(g)。接着把奖励极端的情况去掉(情况太简单或者太难),根据这些奖励适中的情况采样出更多的状态。比如机器臂一开始在某个位置可以抓到东西,然后再离远一点,看能不能抓到,抓到后再离远一点。这种学习方式称为逆向课程学习(reverse curriculum learning)。课程学习是为智能体规划学习的顺序,逆向课程学习是从黄金状态反推。
2.4分层强化学习(hierarchical RL)
我们有多个智能体,一些智能体负责比较高级的东西,它们负责定目标,定完目标以后,再将目标分配给其他的智能体,让其他智能体来执行目标。比如一个学校里校长,教授,研究生都是智能体,现在目标是学习进入QS100。因此校长对教授提出愿景:每年发3篇期刊,教授对研究生提出愿景:做实验。实验做出来,期刊发出来,大家都能得到奖励。每一层的智能体会对下一层智能体提出愿景,下一层再对它的下一层提出新的愿景直到最后一层执行动作。但是如果提出的愿景是下面的智能体无法实现的,就会被讨厌,比如教授让研究生做很难的实验,根本做不出来,教授会被讨厌,得到一个负奖励。每一个智能体都把上层的智能体所提出的愿景当作输入,决定他自己要产生什么输出。

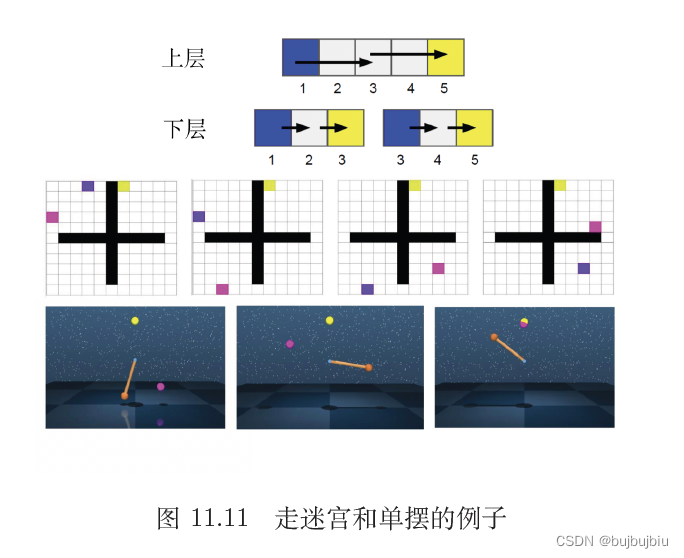
比如在走迷宫游戏中,整体目标是蓝色智能体要走到黄色格子,分为两层智能体学习,第一层为蓝色智能体, 愿景是走到粉色格子,第二层是粉色智能体,提出新的愿景即走到黄色格子,实际上可以分为更多层智能体来实现这个过程。分层强化学习是指将一个复杂的强化学习问题分解成多个小的、 简单的子问题,每个子问题都可以单独用马尔可夫决策过程来建模。这样,我们可以将智能体的策略分为高层次策略和低层次策略,高层次策略根据当前状态决定如何执行低层次策略,从而解决一些复杂的任务。