
hadoop 集群搭建(详细版)
创始人
2025-05-29 08:50:54
0次
hadoop 集群搭建
- 更改主机名
- 映射
- 设置免密
- 同步时间
- 创建工作目录
- 下载jdk
- 安装配置Hadoop
- 修改配置文件
- 向其他节点分发配置完成的程序
- 为Hadoop添加环境变量
- 启动集群
- 初始化
- 启动集群
- web页面
- web页面:[hdfsweb页面](http://192.168.88.128:9870/)
- web页面:[yarnweb页面](http://192.168.88.128:8088/)

更改主机名
三台虚拟机都要更改
# 在node1的节点输入
hostnamectl set-hostname node1.itcast.cn
# 在node2的节点输入
hostnamectl set-hostname node2.itcast.cn
# 在node2的节点输入hostnamectl set-hostname node3.itcast.cn
映射
在每个节点都要操作
vi /etc/hosts # 进入文件
# 在文件最后面添加以下内容
192.168.195.129 node1 node1.itcast.cn
192.168.195.130 node2 node1.itcast.cn
192.168.195.132 node3 node1.itcast.cn
设置免密
在node1上操作做
# 生成公钥(一直回车确认就可以)
ssh-keygen
# 将免密配置到各个节点
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
同步时间
每个节点都要操作
# 下载时间同步工具
yum -y install ntp ntpdate
# 同步时间
ntpdate ntp5.aliyun.com
创建工作目录
每个节点都要创建
# 创建数据存储,下载以及安装目录
mkdir -p /export /data
mkdir -p /export /server
mkdir -p /export /software
下载jdk
将Java压缩包jdk-8u351-linux-x64.tar.gz上传到Linux系统中的/export/server目录中(可以通过xftp我个人认为比较稳定)
# 上传成功后进行解压
tar -zxvf jdk-8u351-linux-x64.tar.gz
# 配置Java的环境变量
vi /etc/profile
export JAVA_HOME=/export/server/jdk1.8.0_241
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
# 重新加载环境变量
source /etc/proflie
安装配置Hadoop
将Hadoop安装文件上传到/export/server目录中
# 对压缩包进行解压
tar -zxvf hadoop-3.3.0-Centos7-64-with-snappy.tar.gz
修改配置文件
进入Hadoop配置文件目录(/export/server/hadoop-3.3.0/etc/hadoop)并且修改以配置文件
cd /export/server/hadoop-3.3.0/etc/hadoop
配置hadoop-env.sh文件
vi hadoop-env.sh
在文件最后
export JAVA_HOME=/export/server/jdk1.8.0_241
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
配置core-site.xml文件
vi core-site.xml
fs.defaultFS hdfs://node1:8020
hadoop.tmp.dir /export/data/hadoop-3.3.0
hadoop.http.staticuser.user root
hadoop.proxyuser.root.hosts *
hadoop.proxyuser.root.groups *
fs.trash.interval 1440
配置hdfs-site.xml文件
vi hdfs-site.xml
dfs.namenode.secondary.http-address node2:9868
配置mapred-site.xml文件
vi mapred-site.xml
mapreduce.framework.name yarn
mapreduce.jobhistory.address node1:10020
mapreduce.jobhistory.webapp.address node1:19888
yarn.app.mapreduce.am.env HADOOP_MAPRED_HOME=${HADOOP_HOME}
mapreduce.map.env HADOOP_MAPRED_HOME=${HADOOP_HOME}
mapreduce.reduce.env HADOOP_MAPRED_HOME=${HADOOP_HOME}
配置yarn-site.xml文件
vi yarn-site.xml
yarn.resourcemanager.hostname node1
yarn.nodemanager.aux-services mapreduce_shuffle
yarn.nodemanager.pmem-check-enabled false
yarn.nodemanager.vmem-check-enabled false
yarn.log-aggregation-enable true
yarn.log.server.url http://node1:19888/jobhistory/logs
yarn.log-aggregation.retain-seconds 604800
配置workers
vi workers
添加到文件
node1
node2
node3
向其他节点分发配置完成的程序
# 进入安装路径
cd /export/server
# 向node2发送配置程序
scp -r hadoop-3.3.0 root@node2:$PWD
# 向node3发送配置程序
scp -r hadoop-3.3.0 root@node3:$PWD
为Hadoop添加环境变量
# 打开环境变量文件
vim /etc/profile
#在文件最后面添加
export HADOOP_HOME=/export/server/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 重新加载环境变量
source /etc/profile
# scp给其他节点
scp /etc/profile node2:/etc/profile
scp /etc/profile node3:/etc/profile
可以在每个节点中输入Hadoop来验证时候配置成功
Hadoop
启动集群
初始化
不要多次执行,不然可能会启动失败,或数据丢失
hdfs namenode -format
启动集群
# 启动hdfs集群
start-dfs.sh
# 启动yarn集群
start-yarn.sh
web页面
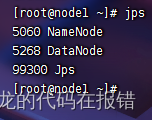
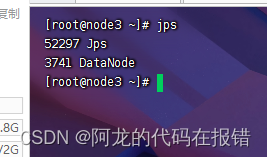
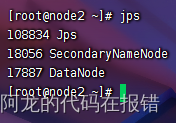
使用jps查询各个节点的进程结果如下即为启动成功
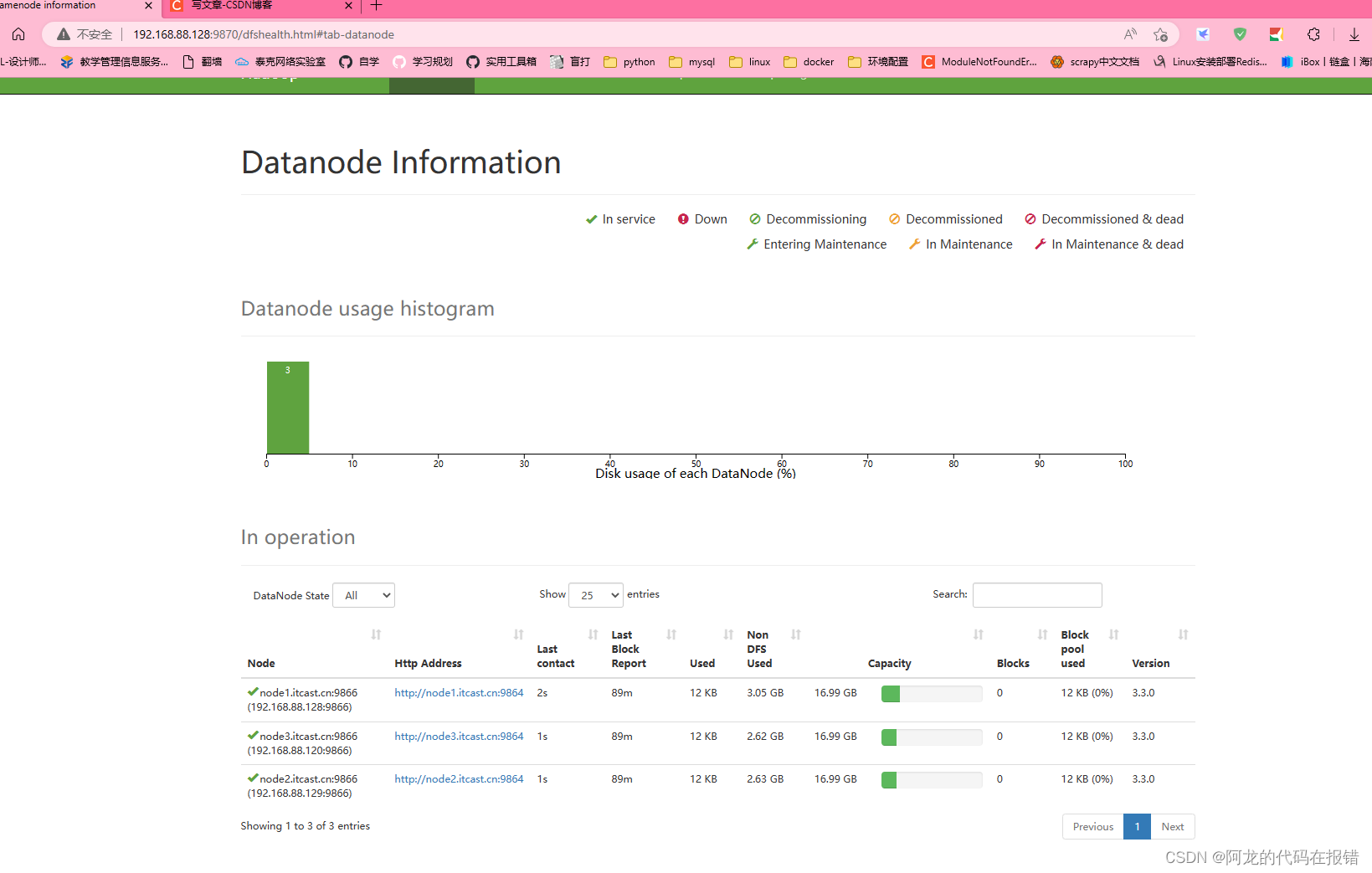
web页面:hdfsweb页面
web页面:yarnweb页面
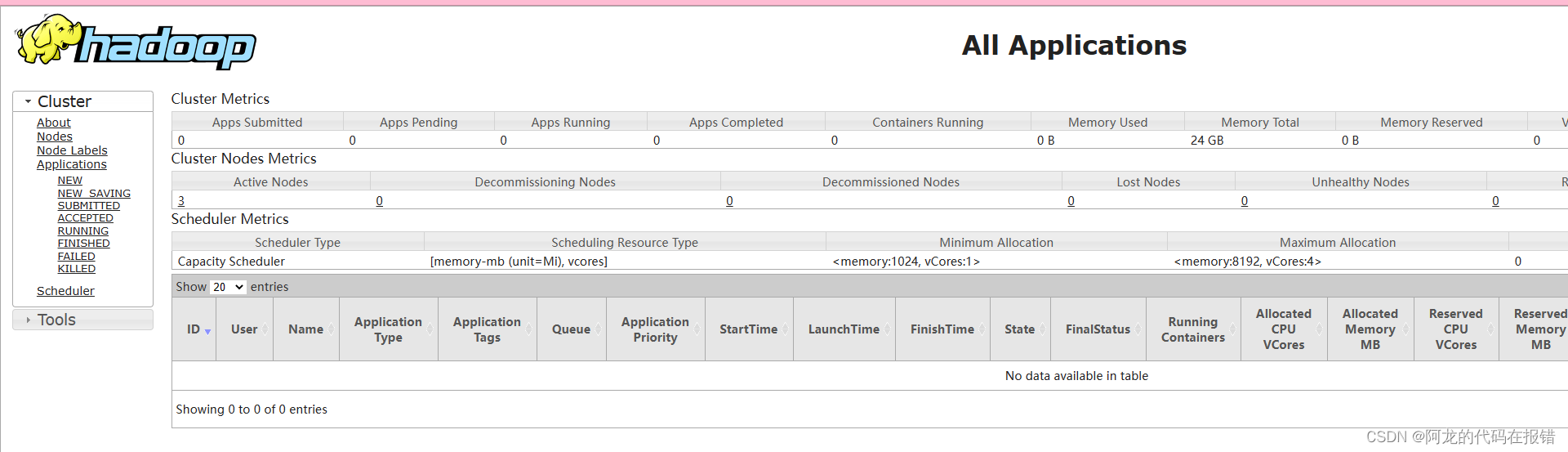
如果还有不理解的或不成功的欢迎下面评论,我把每一步的执行截图补上
愿君前程似锦,未来可期去💯,感谢您的阅读,如果对您有用希望您留下宝贵的点赞和收藏
本文章为本人学习笔记,学习网站为黑马程序员的Hadoop可以一起学习共同进步谢谢,如有请侵权联系,本人会立即删除侵权文章。
相关内容
热门资讯
银行、消金公司助贷余额增速不得...
近日,中国证券报记者从多位业内人士处独家获悉,5月以来,多地金融监管部门对部分中小银行、消金公司下达...
朱鸿接任陈航,担任钉钉科技有限...
消费日报-今朝新闻讯 天眼查显示,6月23日,钉钉科技有限公司发生工商变更,陈航卸任法定代表人、董事...
3日累跌超20%,德创环保:公...
6月25日, 德创环保(603177.SH)公告,公司股票于2026年6月23日、6月24日和6月2...
北京发布2026年第七轮拟供商...
央广网北京6月25日消息(记者门庭婷)6月25日,北京市规划和自然资源委员会网站发布了2026年第七...
开放麦 | 启明创投胡奇:从A...
“2026年,创投圈的浪潮再次翻涌:AI从技术概念走进产业深水区,硬科技创业从“小众赛道” 变成“主...
腾讯孙忠怀:在行业转身处
6月24日,2026腾讯视频年度发布在上海举行。腾讯公司副总裁、腾讯在线视频董事长孙忠怀以《在行业转...
加息,突变!美联储,重磅传来!...
美联储政策路径突生变数。 美国商务部经济分析局最新公布的数据显示,5月个人消费支出(PCE)物价指数...
6月合肥上门收金必看!5步避坑...
2026年6月,合肥黄金市场持续高位运行,不少市民翻出家里闲置的旧金饰、投资金条想变现,上门回收因为...
潮汕女富豪挂帅后加码液冷!祥鑫...
潮汕女强人,带着百亿公司加码液冷散热。 6月24日晚间,祥鑫科技(002965.SZ)公告称,公司董...
马斯克向太空要电,GobiX ...
一场关于「去哪里找电」的全球竞赛,正在朝两个方向展开。 作者|周永亮 编辑| 郑玄 「太空光伏是不是...
原料药行业陷入周期低谷 有药企...
每经记者|许立波 每经编辑|魏文艺 “过完年到现在,我们整个团队每个月都在出差,跑遍了亚非拉、欧美市...
家门口筛查白内障!永顺泽家镇暖...
大众卫生报·新湖南客户端6月25日讯(通讯员 彭雪姣)为切实解决辖区老年性白内障患者异地就医奔波、就...
终于等到!油价马上再大跌,这个...
点击添加图片描述(最多60个字) 编辑 各位车主朋友,好消息接二连三! 继6月18日油价大幅下调...
丈量出海新路 世界酒庄影响力指...
长期以来,全球酒庄评价体系由西方机构主导,且大多局限于单一酒种、单一评价维度,这一局面正逐渐被打破。...
峰瑞资本创始合伙人李丰:从资本...
“2026年,创投圈的浪潮再次翻涌:AI从技术概念走进产业深水区,硬科技创业从“小众赛道” 变成“主...
原创 A...
迈向成熟,还有茁壮成长的机会。 作者 | 方璐 编辑丨于婞 来源 | 野马财经 2026年6月21日...
为企业解锁出海新通道!亚太中小...
6月24日下午,作为2026年APEC中小企业工商论坛的重要组成部分,亚太中小企业国际化合作发展论坛...
君赛生物港股IPO,增聘兴证国...
跟丰宜科技一样,正冲刺港股IPO的上海君赛生物股份有限公司(简称“君赛生物”)增聘一位整体协调人。 ...
圣邦股份明日上市:暗盘涨24%...
雷递网 雷建平 6月25日 圣邦微电子(北京)股份有限公司(简称:“圣邦股份”,股票代码:“0366...
科技“吃肉”,券商跟着“喝汤”...
当科技持续成为市场核心主线,押中硬科技项目的券商也成为被追逐的焦点。 6月24日,半导体零部件概念股...