
MySQL-分库分表方案
一、业务背景
随着业务量的增长,数据量会随之增长,单机情况下DB服务器会面临存储容量、连接数和处理能力的瓶颈,当数据量达到一定量级时,DDL变更时间变长,影响业务可用性,此时需要考虑分库分表,提高SQL性能。
阿里巴巴开发手册规定:单表数据量超过500万行或者单表容量超过2GB时,需要进行分库分表。
为什么是规定500万行?取决于硬件条件:MySQL会提前加载索引到内存中,当一张表的索引太大的时候,内存不够就会进行磁盘IO,这将极大的限制整个数据库的速度。
知识扩展:MySQL表大小限制
MySQL4.0之前,单表最大限制取决于存储引擎,MyISAM支持单表最大限制为 64 PB(67108864 GB)。MySQL4.0之后,支持InnoDB引擎(MySQL5.5 之后的默认存储引擎),Innodb存储数据的策略分为两种:
共享表空间存储方式:Innodb的所有数据保存在一个单独的表空间里面,而这个表空间可以由很多个文件组成,一个表可以跨多个文件存在,所以其大小限制不是文件大小的限制,而受限于表空间。官方指出 Innodb 表空间的最大限制为 64 TB。
独享表空间存储方式:每个表的数据以一个单独的文件(创建表时会自动生成一个xxx.ibd文件)来存放,此时的单表限制,就变成文件系统的大小限制了。文件系统大小受操作系统Block大小限制,Linux操作系统(如CentOS、RedHat)使用ext3文件系统,例如一个4KB大小的块最大能存放文件大小为2TB。
二、分表方案
当单表数据量很大,严重影响业务接口响应时间时(此时MySQL实例负载可能并不高),此时只需要分表。由表容量计算公式TABLE_SIZE = AVG_ROW_SIZE x ROWS,得出分表的两种方案:垂直分表(切分字段)和水平分表(切分记录)。
垂直分表方案
1. 冷热分离
依据二八定律(帕累托法则),频繁使用的字段往往只占所有字段中的一小部分,因此可以将高频使用字段的数据放在一张表,将剩余字段的数据放在另一张表。

查询:select a.entity_id , b.path_trace from table1 a, table2 b where a.id = b.id and a.entity_id = 101
特点:查询时如果没有使用中间件,对代码的改造量较大,并且容易出错,可能实际业务用的不多。
2. 拆分大字段
如果业务表中有必须的Text类型字段,可以将Text类型字段拆分到子表中进行存储。

查询:select a.seq_id, b.comment from table1 a, table2 b where a.id = b.id and a.seq_id = 101;
特点:大字段单独存储,提高sql查询性能。
水平分表方案
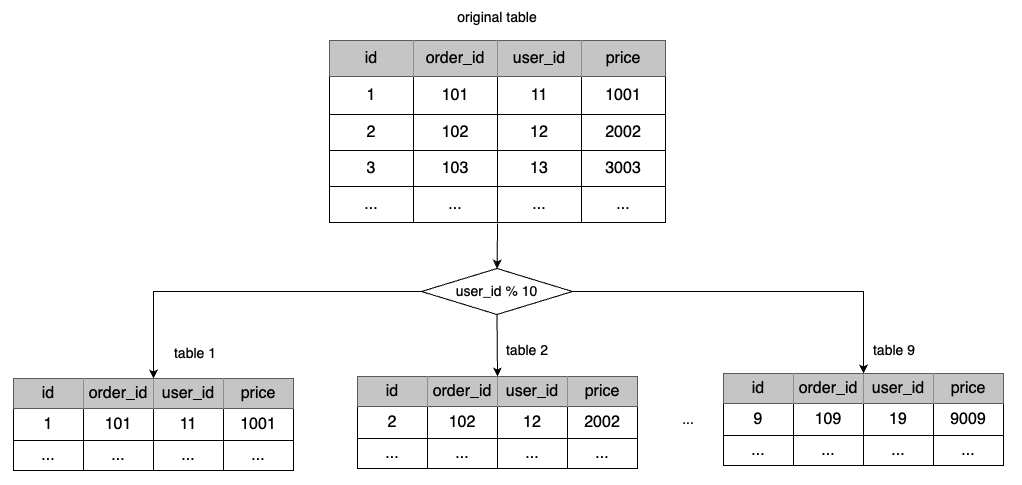
1. 按ID分表
依据业务的增长情况,估算一年后的数据量,将整个数据表拆分为n个子表(参考单表数据不超过500w行规定),拆分过程使用ID取模法,即id % n,将每个数据行拆到对应的子表中。
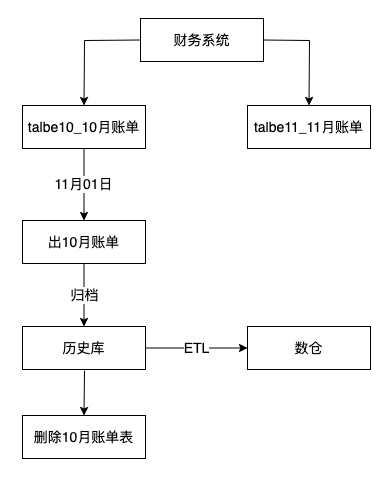
2. 按时间分表
根据业务规模,将时间作为粒度对表进行拆分。
每日表:只存储当天数据。
每月表:起一个定时任务将前一天的数据全部迁移到当月表中。
历史表:同样使用定时任务将超过30天的数据全部迁移到历史表中。
举例,按月维度分表:财务或者计费类系统会在月底统计当月账单,相关的业务执行完后表中的数据是静态化了,之后不会使用到这些数据,当月账单出完后,可以归档到历史库,供数仓ETL做分析报表,确认数据同步到历史库后库,可以从业务库中删除已同步月份的数据,释放表空间。
MySQL分区表
思路和按ID分表相近,只是使用MySQL内部已有的分区概念,基于HASH分区对分区个数进行取模运算。案例:
CREATE TABLE orders (id bigint(20) NOT NULL AUTO_INCREMENT COMMENT'id',order_id varchar(20) NOT NULL COMMENT '订单ID',user_id bigint(20) NOT NULL COMMENT '用户ID',PRIMARY KEY(id, user_id), #分区键必须包含在主键中KEY idx_user_id(user_id)
)
PARTITION BY HASH(user id) #使用哈希分区,分区键user_id
PARTITIONS 20; #20个分区insert into orders(order_id, user_id) values('001',1000),('002',1001),('003',1002),('004',1003),('020',1019);这样就创建了20个分区,对应磁盘上就是20个数据文件(orders#p#p0.ibd一直到orders#p#p19.ibd),来看一下SQL的执行过程。
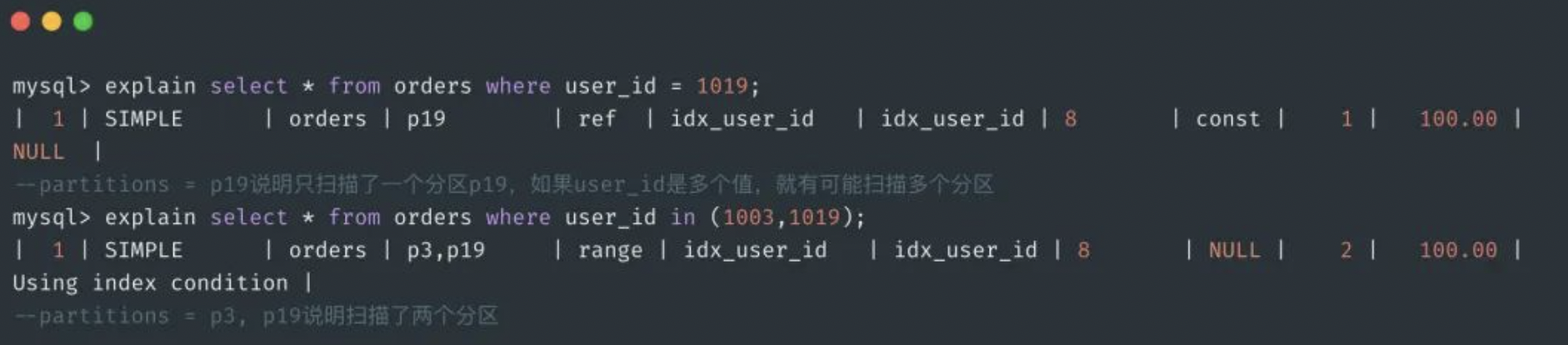
从执行计划可以看到,通过分区键user_id过滤,直接可以定位到数据所在的分区 p19(user_id =1019 % 20 = 19,所以在p19分区上),进而去访问p19对应的数据文件 orders#p#p19.ibd 即可获得数据。
特点:使用MySQL内部实现 SQL 路由的功能,不用去改造业务代码。
三、分库方案
主从架构下,写操作都发生在Master节点,随着业务增长,很多接口RT变长,甚至超时,此时需要通过分库抗高并发。通常也有两种做法:按业务分库和按表分库。
1. 按业务分库
按业务分库其实是做服务拆分,在系统业务量很大的情况下,需求和功能会越来越多,此时需要考虑根据业务类型进行分库,比如将库存、交易、支付相关的接口独立开来。
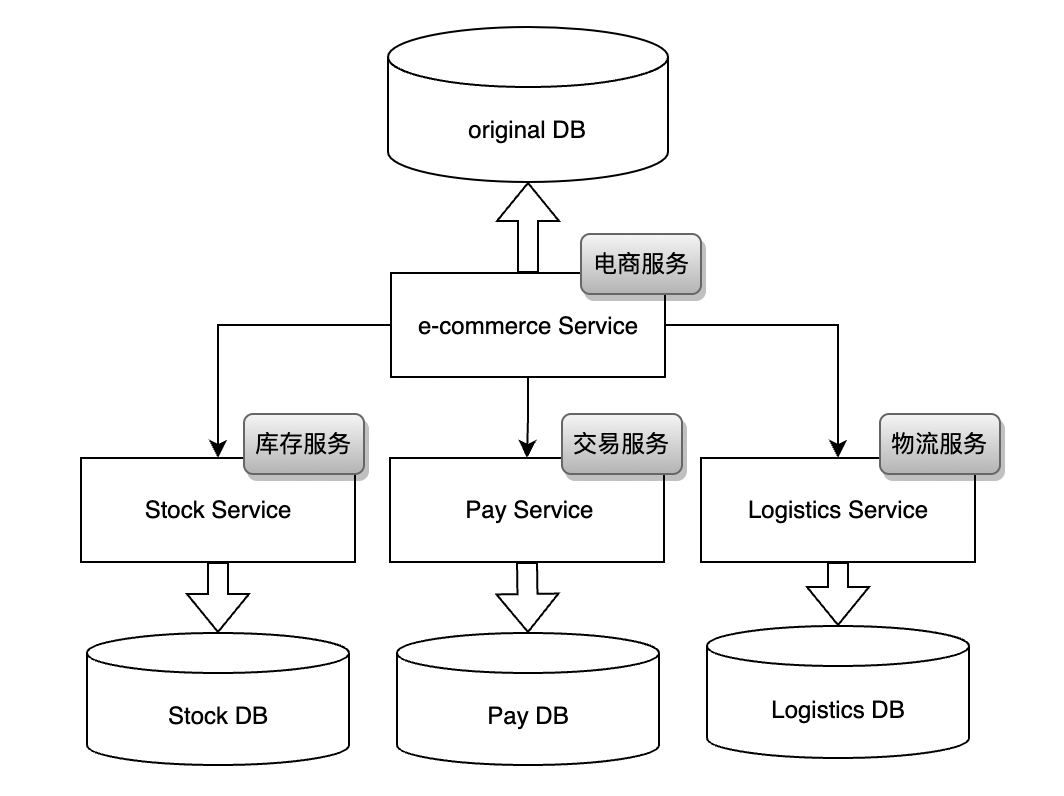
特点:一个库被分成多个库,数据库写入能力提升,接口相应时间变短,同时提高了系统的稳定性。
2. 按表分库
基于垂直分表和水平分表,产生相应的垂直分库和水平分库,即将拆分后的子表存储在拆分后的子库中。垂直分库应用的较少,主要是水平分库。此时可以按ID进行分表,然后将相应的表划分到不同的RDS实例中。
具体查询时候,可以通过ID定位到时那个RDS实例,然后定位到具体的子表。
四、数据库中间件
目前市面上比较常见的数据库中间件按所属层级,主要分为proxy层类型的中间件和client类型的中间件。
- proxy层类型的中间件
该类型的数据库中间件单独部署在一台服务器上,它的优点是,对于系统来说透明,如果遇到中间件需要升级,只需要修改中间件层,缺点也比价明显,数据库中间件单独部署,增加了运维成本。
- client层类型的中间件
使用该类型的中间件,我们只需要在系统中引入一个jar包即可使用,无需额外部署,降低了运维成本,无需代理转发,但它的缺点是,当遇到版本升级时,需要每个系统都升级一遍。
常见的数据库中间件
目前比较常见的中间件包括以下几种:
- Cobar,阿里B2B团队开源,proxy层方案
- TDDL,淘宝团队,client层方案
- Atlas,360开源,proxy层方案
- Sharding-jdbc,当当开源,client层方案,支持分库分表、读写分离、分布式id生成
- Mycat,基于Cobar改造,proxy层方案,支持的功能非常完善,相比sharding-jdbc,只是缺少时间的历练
Cobar
Cobar中间件,属于 proxy 层方案,就是介于应用服务器和数据库服务器之间。应用程序通过 JDBC 驱动访问 Cobar 集群,Cobar 根据 SQL 和分库规则对 SQL 做分解,然后分发到 MySQL 集群不同的数据库实例上执行。该中间件早些年还在用,最近已经没什么人使用了,不支持读写分离、存储过程、跨库 join 和分页等操作。
TDDL
淘宝团队开发,属于 client 层方案。支持基本的 crud 语法和读写分离,但不支持 join、多表查询等语法。目前使用的也不多,因为还依赖淘宝的配置管理系统(diamond)。
Atlas
360 开源,属于 proxy 层方案,以前是有一些公司在用,但是现在用的公司较少了。
Sharding-jdbc
当当开源,属于 client 层方案,目前已经更名为 ShardingSphere。支持分库分表、读写分离、分布式 id 生成、柔性事务(最大努力通知事务、TCC 事务)。而且确实之前使用的公司会比较多一些,目前社区也还一直在开发和维护,还算是比较活跃,是一个可选方案。
小案例:Sharding-jdbc分库分表实践
参考:ShardingJDBC的分库分表实践 - 掘金
订单服务表t_order业务量比较大,现需要进行分库分表
- 分库:根据主键id的奇偶性进行分库,奇数id在ds0,偶数id在ds1
- 分表:根据day_date数值是2022还是2023进行分表
数据库配置
分别建两张表t_order_2022,t_order_2023到两个RDB实例的数据库
CREATE TABLE `t_order2022` (`id` bigint(32) NOT NULL,`user_id` int(11) DEFAULT NULL,`order_id` int(11) DEFAULT NULL,`cloumn` varchar(45) DEFAULT NULL,`day_date` char(8) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `t_order2023` (`id` bigint(32) NOT NULL,`user_id` int(11) DEFAULT NULL,`order_id` int(11) DEFAULT NULL,`cloumn` varchar(45) DEFAULT NULL,`day_date` char(8) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;项目依赖
org.apache.shardingsphere sharding-jdbc-spring-boot-starter ${sharding-sphere.version}
配置文件
server.port=10080spring.shardingsphere.datasource.names=ds0,ds1# 配置第一个数据库
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://localhost:3306/ds0
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=123456# 配置第二个数据库
spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://localhost:3306/ds1
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=123456# 配置t_order表的分库策略spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.sharding-column=id# 自定义分库策略
spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.precise-algorithm-class-name=com.example.shardingjdbc.config.MyDbPreciseShardingAlgorithm# 配置t_order的分表策略
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order$->{2022..2023}
spring.shardingsphere.sharding.tables.t_order.table-strategy.standard.sharding-column=day_date# 自定义分表策略
spring.shardingsphere.sharding.tables.t_order.table-strategy.standard.precise-algorithm-class-name=com.example.shardingjdbc.config.MyTablePreciseShardingAlgorithm# 添加t_order表的id生成策略
spring.shardingsphere.sharding.tables.t_order.key-generator.column=id
spring.shardingsphere.sharding.tables.t_order.key-generator.type=SNOWFLAKE# 打开sql输出日志
spring.shardingsphere.props.sql.show=true# mybatis配置
mybatis.mapper-locations=classpath:mapper/*.xml
mybatis.type-aliases-package=com.example.shardingjdbc.po# 配置日志级别
logging.level.com.echo.shardingjdbc.dao=DEBUG
application.properties配置
tables:t_order:actualDataNodes: ds$->{0..1}.t_order$->{20212..2023}databaseStrategy:standard:preciseAlgorithmClassName: com.example.shardingjdbc.config.MyDbPreciseShardingAlgorithmshardingColumn: idkeyGenerator:column: idtype: SNOWFLAKElogicTable: t_ordertableStrategy:standard:preciseAlgorithmClassName: com.example.shardingjdbc.config.MyTablePreciseShardingAlgorithmshardingColumn: day_date自定义分库分表规则类
package com.example.shardingjdbc.config;import lombok.extern.slf4j.Slf4j;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;import java.util.Collection;
@Slf4j
public class MyDbPreciseShardingAlgorithm implements PreciseShardingAlgorithm{/*** 分片策略* @param availableTargetNames 所有的数据源* @param preciseShardingValue SQL执行时传入的分片值* @return 返回*/@Overridepublic String doSharding(Collection availableTargetNames, PreciseShardingValue preciseShardingValue) {//真实节点availableTargetNames.forEach(a -> log.info("actual node db:{}", a));log.info("logic table name:{}, route column:{}" , preciseShardingValue.getLogicTableName(), preciseShardingValue.getColumnName());//精确分片log.info("column name:{}", preciseShardingValue.getValue());for (String availableTargetName : availableTargetNames) {Long value = preciseShardingValue.getValue();if (("ds"+value%2).equals(availableTargetName)) {return availableTargetName;}}return null;}
} package com.example.shardingjdbc.config;import lombok.extern.slf4j.Slf4j;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;import java.util.Collection;@Slf4j
public class MyTablePreciseShardingAlgorithm implements PreciseShardingAlgorithm{/*** 自定义分表规则* @param availableTargetNames* @param preciseShardingValue* @return*/@Overridepublic String doSharding(Collection availableTargetNames, PreciseShardingValue preciseShardingValue) {//真实节点availableTargetNames.forEach(a -> log.info("actual node table:{}", a));log.info("logic table name:{}, route column:{}", preciseShardingValue.getLogicTableName(), preciseShardingValue.getColumnName());//精确分片log.info("column value:{}", preciseShardingValue.getValue());for (String availableTargetName : availableTargetNames) {if (("t_order"+preciseShardingValue.getValue()).equals(availableTargetName)) {return availableTargetName;}}return null;}
} Mycat
基于 Cobar 改造的,属于 proxy 层方案,支持的功能非常完善,而且目前应该是非常火的而且不断流行的数据库中间件,社区很活跃,也有一些公司开始在用,相比于 Sharding jdbc 来说,年轻一些,经历的锤炼少一些。
小结
- 中小型公司选用 Sharding-jdbc,client 层方案轻便,而且维护成本低,不需要额外增派人手,而且中小型公司系统复杂度会低一些,项目也没那么多;
- 中大型公司最好还是选用 Mycat 这类 proxy 层方案,因为可能大公司系统和项目非常多,团队很大,人员充足,那么最好是专门指定一些人研究和维护 Mycat,然后大量项目直接透明使用即可。
五、分库后面临的问题
1. 跨库Join问题
分库之后,数据库分布在不同RDS实例中,根据MySQL开发规范,一般是禁止跨库Join。通常采用全局表和数据同步方案解决垮库Join问题。
- 全局表
使用MyCat做分库分表,有一个全局表概念,每个DataNode上有一份全量数据,例如一些数据字典表,数据很少修改,可以避免垮库Join的问题。
- 数据同步
将一份RDS实例上的数据同步到另一份上,解决垮库 Join问题。比较依赖同步工具的稳定性,如果同步有延迟会导致数据不一致,产生脏数据,需要做好风险评估和兜底。
2. 分布式事务
分布式事务常用的解决方案:
- 两阶段提交
- TCC
- 本地消息表(业界使用较多)
- 可靠消息最终一致性
- 最大努力通知
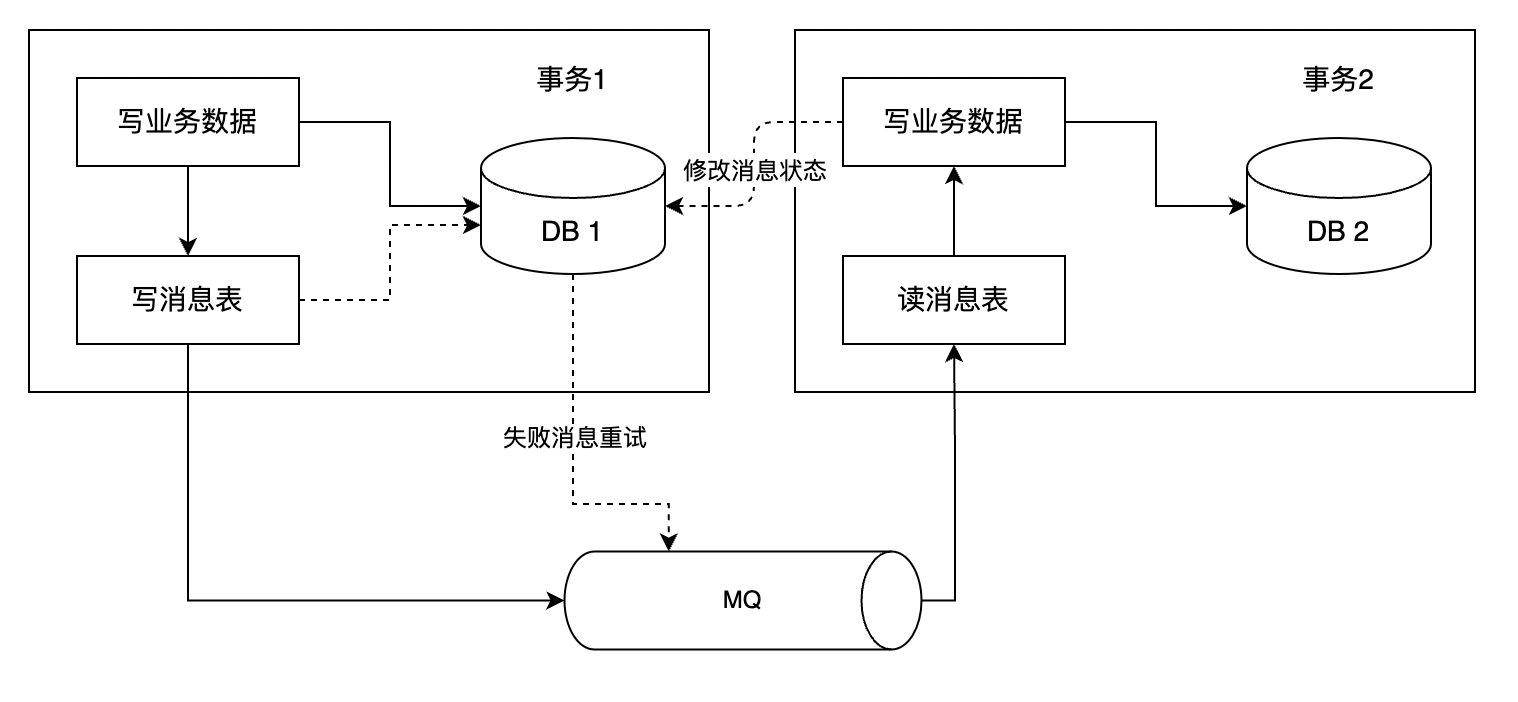
可靠消息最终一致性方案图
3.分布式全局唯一ID
如果每个拆分后的RDS实例使用自增ID作为主键,则会出现ID重复的问题,可以使用Snowflake算法生成唯一ID。
4.垮库函数处理
使用max、min、sum等进行统计和计算时,需要再每个分片数据源上进行相应的函数处理,然后将各个结果集进行二次处理,最终将处理结果返回。
六、总结
在实际开发过程中,遇到核心业务表增长过快的情况下,如果执行SQL语句出现了性能瓶颈,考虑分库分表。拆分策略需要结合具体的应用场景,选择合适的方案,从而支撑业务的快速增长和系统的快速迭代。
上一篇:STM32TIM定时器