
pytorch1.2.0训练病害分类项目一
利用pytorch1.2.0+cuda10.0+conda的虚拟环境+pycharm环境
pytorch1.2.0+python3.6_彩色面团儿的博客-CSDN博客
目录
一、文件结构:
(一)总结构
(二)每个文件夹巨巨巨详细说明
二、数据集准备:
三、训练前准备txt_annotation.py生成两个txt文件
四、开始训练模型
五、预测
1、训练完成后,看logs文件下有对应训练好的权值
2、打开classification.py修改三个参数
3、直接运行predict.py ,无需修改任何参数
4、看结果
一、文件结构:
(一)总结构

(二)每个文件夹巨巨巨详细说明
1、datasets:放图片数据集(包括训练集和测试集)


rot/rust/scab是我的三分类,大家可以分自己的类。test文件夹里和train一样。但是图片可以不一样。对于图片一般9:1.也有的拿10000张图,分成5份,轮着4份做训练,1份做测试,轮5次,看最后的效果loss。
2、img随便放三四张,用于最后的预测

最后的最后一步,预测效果如下:

3、logs:不需要自己放,这个文件夹是在你运行train时训练后产生的权重文件,自动生成。内容如下:

4、model_data时网上的一些模型训练权重,可以作为训练的时候的预训练权重,加上预训练就不随机效果更好,这个不分数据集,都可以用。
具体影响参考博文: 研究total loss与val loss以及预训练权重

5、nets,utils:一些网络模型和配置文件。

6、py文件

二、数据集准备:
以train/rot为例,注意命名格式,之前rot(1)之类的不行,识别不来。
可以参考博文:
https://mp.csdn.net/mp_blog/creation/editor/129239941
https://mp.csdn.net/mp_blog/creation/editor/129382801

三、训练前准备txt_annotation.py生成两个txt文件

txt文件中是自己所要去区分的种类,训练前一定要修改classes,使其对应自己的数据集。
打开txt_annotation.py,修改calsses=["",""]
import os
from os import getcwd
from utils.utils import get_classesclasses=["rot","rust","scab"]
sets = ["test","train"]wd = getcwd()
for se in sets:datasets_path = "datasets/" + setypes_name = os.listdir(datasets_path)list_file = open('cls_' + se + '.txt', 'w')for type_name in types_name:if type_name not in classes:continuecls_id = classes.index(type_name)photos_path = os.path.join(datasets_path, type_name)photos_name = os.listdir(photos_path)for photo_name in photos_name:# _, postfix = os.path.splitext(photo_name)# if postfix not in ['.jpg', '.png', '.jpeg']:# continuelist_file.write(str(cls_id) + ";" + '%s' % ( os.path.join(photos_path, photo_name)))list_file.write('\n')list_file.close()四、开始训练模型
tran.py文件(训练文件)需要修改的地方都有注释,很详细。
import osimport numpy as np
import torch
import torch.backends.cudnn as cudnn
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoaderfrom nets import get_model_from_name
from utils.callbacks import LossHistory
from utils.dataloader import DataGenerator, detection_collate
from utils.utils import (download_weights, get_classes, get_lr_scheduler,set_optimizer_lr, show_config, weights_init)
from utils.utils_fit import fit_one_epochif __name__ == "__main__":#----------------------------------------------------## 是否使用Cuda# 没有GPU可以设置成False#----------------------------------------------------#Cuda =True#---------------------------------------------------------------------## distributed 用于指定是否使用单机多卡分布式运行# 终端指令仅支持Ubuntu。CUDA_VISIBLE_DEVICES用于在Ubuntu下指定显卡。# Windows系统下默认使用DP模式调用所有显卡,不支持DDP。# DP模式:# 设置 distributed = False# 在终端中输入 CUDA_VISIBLE_DEVICES=0,1 python train.py# DDP模式:# 设置 distributed = True# 在终端中输入 CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 train.py#---------------------------------------------------------------------#distributed = False#---------------------------------------------------------------------## sync_bn 是否使用sync_bn,DDP模式多卡可用#---------------------------------------------------------------------#sync_bn = False#---------------------------------------------------------------------## fp16 是否使用混合精度训练# 可减少约一半的显存、需要pytorch1.7.1以上#---------------------------------------------------------------------#fp16 = False#----------------------------------------------------## 训练自己的数据集的时候一定要注意修改classes_path# 修改成自己对应的种类的txt#----------------------------------------------------#classes_path = 'model_data/cls_classes.txt'#----------------------------------------------------## 输入的图片大小#----------------------------------------------------#input_shape = [224, 224]#------------------------------------------------------## 所用模型种类:# mobilenetv2、# resnet18、resnet34、resnet50、resnet101、resnet152# vgg11、vgg13、vgg16、vgg11_bn、vgg13_bn、vgg16_bn、# vit_b_16、# swin_transformer_tiny、swin_transformer_small、swin_transformer_base#------------------------------------------------------## backbone = "mobilenetv2"backbone = "resnet50"#----------------------------------------------------------------------------------------------------------------------------## 是否使用主干网络的预训练权重,此处使用的是主干的权重,因此是在模型构建的时候进行加载的。# 如果设置了model_path,则主干的权值无需加载,pretrained的值无意义。# 如果不设置model_path,pretrained = True,此时仅加载主干开始训练。# 如果不设置model_path,pretrained = False,Freeze_Train = Fasle,此时从0开始训练,且没有冻结主干的过程。#----------------------------------------------------------------------------------------------------------------------------#pretrained = True#----------------------------------------------------------------------------------------------------------------------------## 权值文件的下载请看README,可以通过网盘下载。模型的 预训练权重 对不同数据集是通用的,因为特征是通用的。# 模型的 预训练权重 比较重要的部分是 主干特征提取网络的权值部分,用于进行特征提取。# 预训练权重对于99%的情况都必须要用,不用的话主干部分的权值太过随机,特征提取效果不明显,网络训练的结果也不会好## 如果训练过程中存在中断训练的操作,可以将model_path设置成logs文件夹下的权值文件,将已经训练了一部分的权值再次载入。# 同时修改下方的 冻结阶段 或者 解冻阶段 的参数,来保证模型epoch的连续性。# # 当model_path = ''的时候不加载整个模型的权值。## 此处使用的是整个模型的权重,因此是在train.py进行加载的,pretrain不影响此处的权值加载。# 如果想要让模型从主干的预训练权值开始训练,则设置model_path = '',pretrain = True,此时仅加载主干。# 如果想要让模型从0开始训练,则设置model_path = '',pretrain = Fasle,此时从0开始训练。#----------------------------------------------------------------------------------------------------------------------------#model_path = "model_data/resnet50-19c8e357.pth"#----------------------------------------------------------------------------------------------------------------------------## 训练分为两个阶段,分别是冻结阶段和解冻阶段。设置冻结阶段是为了满足机器性能不足的同学的训练需求。# 冻结训练需要的显存较小,显卡非常差的情况下,可设置Freeze_Epoch等于UnFreeze_Epoch,此时仅仅进行冻结训练。# # 在此提供若干参数设置建议,各位训练者根据自己的需求进行灵活调整:# (一)从整个模型的预训练权重开始训练: # Adam:# Init_Epoch = 0,Freeze_Epoch = 50,UnFreeze_Epoch = 100,Freeze_Train = True,optimizer_type = 'adam',Init_lr = 1e-3。(冻结)# Init_Epoch = 0,UnFreeze_Epoch = 100,Freeze_Train = False,optimizer_type = 'adam',Init_lr = 1e-3。(不冻结)# SGD:# Init_Epoch = 0,Freeze_Epoch = 50,UnFreeze_Epoch = 200,Freeze_Train = True,optimizer_type = 'sgd',Init_lr = 1e-2。(冻结)# Init_Epoch = 0,UnFreeze_Epoch = 200,Freeze_Train = False,optimizer_type = 'sgd',Init_lr = 1e-2。(不冻结)# 其中:UnFreeze_Epoch可以在100-300之间调整。# (二)从0开始训练:# Adam:# Init_Epoch = 0,UnFreeze_Epoch = 300,Unfreeze_batch_size >= 16,Freeze_Train = False,optimizer_type = 'adam',Init_lr = 1e-3。(不冻结)# SGD:# Init_Epoch = 0,UnFreeze_Epoch = 300,Unfreeze_batch_size >= 16,Freeze_Train = False,optimizer_type = 'sgd',Init_lr = 1e-2。(不冻结)# 其中:UnFreeze_Epoch尽量不小于300。# (三)batch_size的设置:# 在显卡能够接受的范围内,以大为好。显存不足与数据集大小无关,提示显存不足(OOM或者CUDA out of memory)请调小batch_size。# 受到BatchNorm层影响,batch_size最小为2,不能为1。# 正常情况下Freeze_batch_size建议为Unfreeze_batch_size的1-2倍。不建议设置的差距过大,因为关系到学习率的自动调整。#----------------------------------------------------------------------------------------------------------------------------##------------------------------------------------------------------## 冻结阶段训练参数# 此时模型的主干被冻结了,特征提取网络不发生改变# 占用的显存较小,仅对网络进行微调# Init_Epoch 模型当前开始的训练世代,其值可以大于Freeze_Epoch,如设置:# Init_Epoch = 60、Freeze_Epoch = 50、UnFreeze_Epoch = 100# 会跳过冻结阶段,直接从60代开始,并调整对应的学习率。# (断点续练时使用)# Freeze_Epoch 模型冻结训练的Freeze_Epoch# (当Freeze_Train=False时失效)# Freeze_batch_size 模型冻结训练的batch_size# (当Freeze_Train=False时失效)#------------------------------------------------------------------#Init_Epoch = 0Freeze_Epoch = 50Freeze_batch_size = 32#------------------------------------------------------------------## 解冻阶段训练参数# 此时模型的主干不被冻结了,特征提取网络会发生改变# 占用的显存较大,网络所有的参数都会发生改变# UnFreeze_Epoch 模型总共训练的epoch# Unfreeze_batch_size 模型在解冻后的batch_size#------------------------------------------------------------------#UnFreeze_Epoch = 100 #200Unfreeze_batch_size = 32#------------------------------------------------------------------## Freeze_Train 是否进行冻结训练# 默认先冻结主干训练后解冻训练。#------------------------------------------------------------------#Freeze_Train = True#------------------------------------------------------------------## 其它训练参数:学习率、优化器、学习率下降有关#------------------------------------------------------------------##------------------------------------------------------------------## Init_lr 模型的最大学习率# 当使用Adam优化器时建议设置 Init_lr=1e-3# 当使用SGD优化器时建议设置 Init_lr=1e-2# Min_lr 模型的最小学习率,默认为最大学习率的0.01#------------------------------------------------------------------#Init_lr = 1e-2Min_lr = Init_lr * 0.01#------------------------------------------------------------------## optimizer_type 使用到的优化器种类,可选的有adam、sgd# 当使用Adam优化器时建议设置 Init_lr=1e-3# 当使用SGD优化器时建议设置 Init_lr=1e-2# momentum 优化器内部使用到的momentum参数# weight_decay 权值衰减,可防止过拟合# 使用adam优化器时会有错误,建议设置为0#------------------------------------------------------------------#optimizer_type = "sgd"momentum = 0.9weight_decay = 5e-4#------------------------------------------------------------------## lr_decay_type 使用到的学习率下降方式,可选的有step、cos#------------------------------------------------------------------#lr_decay_type = "cos"#------------------------------------------------------------------## save_period 多少个epoch保存一次权值#------------------------------------------------------------------#save_period = 10#------------------------------------------------------------------## save_dir 权值与日志文件保存的文件夹#------------------------------------------------------------------#save_dir = 'logs'#------------------------------------------------------------------## num_workers 用于设置是否使用多线程读取数据# 开启后会加快数据读取速度,但是会占用更多内存# 内存较小的电脑可以设置为2或者0 #------------------------------------------------------------------#num_workers = 4#------------------------------------------------------## train_annotation_path 训练图片路径和标签# test_annotation_path 验证图片路径和标签(使用测试集代替验证集)#------------------------------------------------------#train_annotation_path = "cls_train.txt"test_annotation_path = 'cls_test.txt'#------------------------------------------------------## 设置用到的显卡#------------------------------------------------------#ngpus_per_node = torch.cuda.device_count()if distributed:dist.init_process_group(backend="nccl")local_rank = int(os.environ["LOCAL_RANK"])rank = int(os.environ["RANK"])device = torch.device("cuda", local_rank)if local_rank == 0:print(f"[{os.getpid()}] (rank = {rank}, local_rank = {local_rank}) training...")print("Gpu Device Count : ", ngpus_per_node)else:device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')local_rank = 0rank = 0#----------------------------------------------------## 下载预训练权重#----------------------------------------------------#if pretrained:if distributed:if local_rank == 0:download_weights(backbone) dist.barrier()else:download_weights(backbone)#------------------------------------------------------## 获取classes#------------------------------------------------------#class_names, num_classes = get_classes(classes_path)if backbone not in ['vit_b_16', 'swin_transformer_tiny', 'swin_transformer_small', 'swin_transformer_base']:model = get_model_from_name[backbone](num_classes = num_classes, pretrained = pretrained)else:model = get_model_from_name[backbone](input_shape = input_shape, num_classes = num_classes, pretrained = pretrained)if not pretrained:weights_init(model)if model_path != "":#------------------------------------------------------## 权值文件请看README,百度网盘下载#------------------------------------------------------#if local_rank == 0:print('Load weights {}.'.format(model_path))#------------------------------------------------------## 根据预训练权重的Key和模型的Key进行加载#------------------------------------------------------#model_dict = model.state_dict()pretrained_dict = torch.load(model_path, map_location = device)load_key, no_load_key, temp_dict = [], [], {}for k, v in pretrained_dict.items():if k in model_dict.keys() and np.shape(model_dict[k]) == np.shape(v):temp_dict[k] = vload_key.append(k)else:no_load_key.append(k)model_dict.update(temp_dict)model.load_state_dict(model_dict)#------------------------------------------------------## 显示没有匹配上的Key#------------------------------------------------------#if local_rank == 0:print("\nSuccessful Load Key:", str(load_key)[:500], "……\nSuccessful Load Key Num:", len(load_key))print("\nFail To Load Key:", str(no_load_key)[:500], "……\nFail To Load Key num:", len(no_load_key))print("\n\033[1;33;44m温馨提示,head部分没有载入是正常现象,Backbone部分没有载入是错误的。\033[0m")#----------------------## 记录Loss#----------------------#if local_rank == 0:loss_history = LossHistory(save_dir, model, input_shape=input_shape)else:loss_history = None#------------------------------------------------------------------## torch 1.2不支持amp,建议使用torch 1.7.1及以上正确使用fp16# 因此torch1.2这里显示"could not be resolve"#------------------------------------------------------------------#if fp16:from torch.cuda.amp import GradScaler as GradScalerscaler = GradScaler()else:scaler = Nonemodel_train = model.train()#----------------------------## 多卡同步Bn#----------------------------#if sync_bn and ngpus_per_node > 1 and distributed:model_train = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model_train)elif sync_bn:print("Sync_bn is not support in one gpu or not distributed.")if Cuda:if distributed:#----------------------------## 多卡平行运行#----------------------------#model_train = model_train.cuda(local_rank)model_train = torch.nn.parallel.DistributedDataParallel(model_train, device_ids=[local_rank], find_unused_parameters=True)else:model_train = torch.nn.DataParallel(model)cudnn.benchmark = Truemodel_train = model_train.cuda()#---------------------------## 读取数据集对应的txt#---------------------------#with open(train_annotation_path, encoding='utf-8') as f:train_lines = f.readlines()with open(test_annotation_path, encoding='utf-8') as f:val_lines = f.readlines()num_train = len(train_lines)num_val = len(val_lines)np.random.seed(10101)np.random.shuffle(train_lines)np.random.seed(None)if local_rank == 0:show_config(num_classes = num_classes, backbone = backbone, model_path = model_path, input_shape = input_shape, \Init_Epoch = Init_Epoch, Freeze_Epoch = Freeze_Epoch, UnFreeze_Epoch = UnFreeze_Epoch, Freeze_batch_size = Freeze_batch_size, Unfreeze_batch_size = Unfreeze_batch_size, Freeze_Train = Freeze_Train, \Init_lr = Init_lr, Min_lr = Min_lr, optimizer_type = optimizer_type, momentum = momentum, lr_decay_type = lr_decay_type, \save_period = save_period, save_dir = save_dir, num_workers = num_workers, num_train = num_train, num_val = num_val)#---------------------------------------------------------## 总训练世代指的是遍历全部数据的总次数# 总训练步长指的是梯度下降的总次数 # 每个训练世代包含若干训练步长,每个训练步长进行一次梯度下降。# 此处仅建议最低训练世代,上不封顶,计算时只考虑了解冻部分#----------------------------------------------------------#wanted_step = 3e4 if optimizer_type == "sgd" else 1e4total_step = num_train // Unfreeze_batch_size * UnFreeze_Epochif total_step <= wanted_step:wanted_epoch = wanted_step // (num_train // Unfreeze_batch_size) + 1print("\n\033[1;33;44m[Warning] 使用%s优化器时,建议将训练总步长设置到%d以上。\033[0m"%(optimizer_type, wanted_step))print("\033[1;33;44m[Warning] 本次运行的总训练数据量为%d,Unfreeze_batch_size为%d,共训练%d个Epoch,计算出总训练步长为%d。\033[0m"%(num_train, Unfreeze_batch_size, UnFreeze_Epoch, total_step))print("\033[1;33;44m[Warning] 由于总训练步长为%d,小于建议总步长%d,建议设置总世代为%d。\033[0m"%(total_step, wanted_step, wanted_epoch))#------------------------------------------------------## 主干特征提取网络特征通用,冻结训练可以加快训练速度# 也可以在训练初期防止权值被破坏。# Init_Epoch为起始世代# Freeze_Epoch为冻结训练的世代# UnFreeze_Epoch总训练世代# 提示OOM或者显存不足请调小Batch_size#------------------------------------------------------#if True:UnFreeze_flag = False#------------------------------------## 冻结一定部分训练#------------------------------------#if Freeze_Train:model.freeze_backbone()#-------------------------------------------------------------------## 如果不冻结训练的话,直接设置batch_size为Unfreeze_batch_size#-------------------------------------------------------------------#batch_size = Freeze_batch_size if Freeze_Train else Unfreeze_batch_size#-------------------------------------------------------------------## 判断当前batch_size,自适应调整学习率#-------------------------------------------------------------------#nbs = 64lr_limit_max = 1e-3 if optimizer_type == 'adam' else 1e-1lr_limit_min = 1e-4 if optimizer_type == 'adam' else 5e-4if backbone in ['vit_b_16', 'swin_transformer_tiny', 'swin_transformer_small', 'swin_transformer_base']:nbs = 256lr_limit_max = 1e-3 if optimizer_type == 'adam' else 1e-1lr_limit_min = 1e-5 if optimizer_type == 'adam' else 5e-4Init_lr_fit = min(max(batch_size / nbs * Init_lr, lr_limit_min), lr_limit_max)Min_lr_fit = min(max(batch_size / nbs * Min_lr, lr_limit_min * 1e-2), lr_limit_max * 1e-2)optimizer = {'adam' : optim.Adam(model_train.parameters(), Init_lr_fit, betas = (momentum, 0.999), weight_decay=weight_decay),'sgd' : optim.SGD(model_train.parameters(), Init_lr_fit, momentum = momentum, nesterov=True)}[optimizer_type]#---------------------------------------## 获得学习率下降的公式#---------------------------------------#lr_scheduler_func = get_lr_scheduler(lr_decay_type, Init_lr_fit, Min_lr_fit, UnFreeze_Epoch)#---------------------------------------## 判断每一个世代的长度#---------------------------------------#epoch_step = num_train // batch_sizeepoch_step_val = num_val // batch_sizeif epoch_step == 0 or epoch_step_val == 0:raise ValueError("数据集过小,无法继续进行训练,请扩充数据集。")train_dataset = DataGenerator(train_lines, input_shape, True)val_dataset = DataGenerator(val_lines, input_shape, False)if distributed:train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset, shuffle=True,)val_sampler = torch.utils.data.distributed.DistributedSampler(val_dataset, shuffle=False,)batch_size = batch_size // ngpus_per_nodeshuffle = Falseelse:train_sampler = Noneval_sampler = Noneshuffle = Truegen = DataLoader(train_dataset, shuffle=shuffle, batch_size=batch_size, num_workers=num_workers, pin_memory=True, drop_last=True, collate_fn=detection_collate, sampler=train_sampler)gen_val = DataLoader(val_dataset, shuffle=shuffle, batch_size=batch_size, num_workers=num_workers, pin_memory=True,drop_last=True, collate_fn=detection_collate, sampler=val_sampler)#---------------------------------------## 开始模型训练#---------------------------------------#for epoch in range(Init_Epoch, UnFreeze_Epoch):#---------------------------------------## 如果模型有冻结学习部分# 则解冻,并设置参数#---------------------------------------#if epoch >= Freeze_Epoch and not UnFreeze_flag and Freeze_Train:batch_size = Unfreeze_batch_size#-------------------------------------------------------------------## 判断当前batch_size,自适应调整学习率#-------------------------------------------------------------------#nbs = 64lr_limit_max = 1e-3 if optimizer_type == 'adam' else 1e-1lr_limit_min = 1e-4 if optimizer_type == 'adam' else 5e-4if backbone in ['vit_b_16', 'swin_transformer_tiny', 'swin_transformer_small', 'swin_transformer_base']:nbs = 256lr_limit_max = 1e-3 if optimizer_type == 'adam' else 1e-1lr_limit_min = 1e-5 if optimizer_type == 'adam' else 5e-4Init_lr_fit = min(max(batch_size / nbs * Init_lr, lr_limit_min), lr_limit_max)Min_lr_fit = min(max(batch_size / nbs * Min_lr, lr_limit_min * 1e-2), lr_limit_max * 1e-2)#---------------------------------------## 获得学习率下降的公式#---------------------------------------#lr_scheduler_func = get_lr_scheduler(lr_decay_type, Init_lr_fit, Min_lr_fit, UnFreeze_Epoch)model.Unfreeze_backbone()epoch_step = num_train // batch_sizeepoch_step_val = num_val // batch_sizeif epoch_step == 0 or epoch_step_val == 0:raise ValueError("数据集过小,无法继续进行训练,请扩充数据集。")if distributed:batch_size = batch_size // ngpus_per_nodegen = DataLoader(train_dataset, shuffle=shuffle, batch_size=batch_size, num_workers=num_workers, pin_memory=True,drop_last=True, collate_fn=detection_collate, sampler=train_sampler)gen_val = DataLoader(val_dataset, shuffle=shuffle, batch_size=batch_size, num_workers=num_workers, pin_memory=True,drop_last=True, collate_fn=detection_collate, sampler=val_sampler)UnFreeze_flag = Trueif distributed:train_sampler.set_epoch(epoch)set_optimizer_lr(optimizer, lr_scheduler_func, epoch)fit_one_epoch(model_train, model, loss_history, optimizer, epoch, epoch_step, epoch_step_val, gen, gen_val, UnFreeze_Epoch, Cuda, fp16, scaler, save_period, save_dir, local_rank)if local_rank == 0:loss_history.writer.close()
训练过程:


五、预测
1、训练完成后,看logs文件下有对应训练好的权值

2、打开classification.py修改三个参数
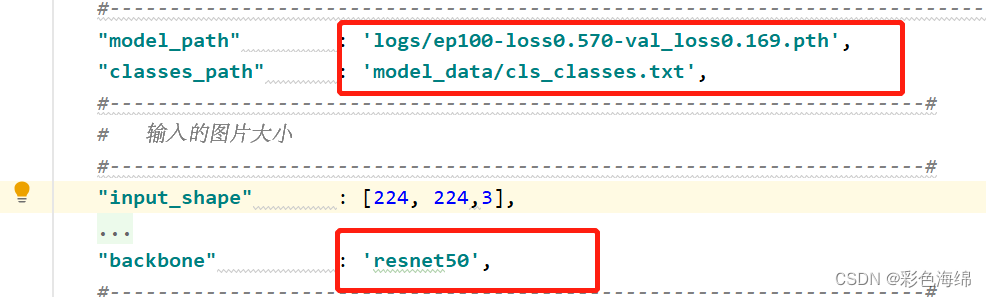
使用自己训练好的模型进行预测一定要修改model_path和classes_path和所用模型网络!
import matplotlib.pyplot as plt
import numpy as np
import torch
from torch import nnfrom nets import get_model_from_name
from utils.utils import (cvtColor, get_classes, letterbox_image,preprocess_input, show_config)#--------------------------------------------#
# 使用自己训练好的模型预测需要修改3个参数
# model_path和classes_path和backbone都需要修改!
#--------------------------------------------#
class Classification(object):_defaults = {#--------------------------------------------------------------------------## 使用自己训练好的模型进行预测一定要修改model_path和classes_path!# model_path指向logs文件夹下的权值文件,classes_path指向model_data下的txt# 如果出现shape不匹配,同时要注意训练时的model_path和classes_path参数的修改#--------------------------------------------------------------------------#"model_path" : 'logs/ep010-loss0.771-val_loss0.612.pth',"classes_path" : 'model_data/cls_classes.txt',#--------------------------------------------------------------------## 输入的图片大小#--------------------------------------------------------------------#"input_shape" : [224, 224,3],#--------------------------------------------------------------------## 所用模型种类:# mobilenetv2、# resnet18、resnet34、resnet50、resnet101、resnet152# vgg11、vgg13、vgg16、vgg11_bn、vgg13_bn、vgg16_bn、# vit_b_16、# swin_transformer_tiny、swin_transformer_small、swin_transformer_base#--------------------------------------------------------------------#"backbone" : 'mobilenetv2',#--------------------------------------------------------------------## 该变量用于控制是否使用letterbox_image对输入图像进行不失真的resize# 否则对图像进行CenterCrop#--------------------------------------------------------------------#"letterbox_image" : False,#-------------------------------## 是否使用Cuda# 没有GPU可以设置成False#-------------------------------#"cuda" : True}@classmethoddef get_defaults(cls, n):if n in cls._defaults:return cls._defaults[n]else:return "Unrecognized attribute name '" + n + "'"#---------------------------------------------------## 初始化classification#---------------------------------------------------#def __init__(self, **kwargs):self.__dict__.update(self._defaults)for name, value in kwargs.items():setattr(self, name, value)#---------------------------------------------------## 获得种类#---------------------------------------------------#self.class_names, self.num_classes = get_classes(self.classes_path)self.generate()show_config(**self._defaults)#---------------------------------------------------## 获得所有的分类#---------------------------------------------------#def generate(self):#---------------------------------------------------## 载入模型与权值#---------------------------------------------------#if self.backbone not in ['vit_b_16', 'swin_transformer_tiny', 'swin_transformer_small', 'swin_transformer_base']:self.model = get_model_from_name[self.backbone](num_classes = self.num_classes, pretrained = False)else:self.model = get_model_from_name[self.backbone](input_shape = self.input_shape, num_classes = self.num_classes, pretrained = False)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')self.model.load_state_dict(torch.load(self.model_path, map_location=device))self.model = self.model.eval()print('{} model, and classes loaded.'.format(self.model_path))if self.cuda:self.model = nn.DataParallel(self.model)self.model = self.model.cuda()#---------------------------------------------------## 检测图片#---------------------------------------------------#def detect_image(self, image):#---------------------------------------------------------## 在这里将图像转换成RGB图像,防止灰度图在预测时报错。# 代码仅仅支持RGB图像的预测,所有其它类型的图像都会转化成RGB#---------------------------------------------------------#image = cvtColor(image)#---------------------------------------------------## 对图片进行不失真的resize#---------------------------------------------------#image_data = letterbox_image(image, [self.input_shape[1], self.input_shape[0]], self.letterbox_image)#---------------------------------------------------------## 归一化+添加上batch_size维度+转置#---------------------------------------------------------#image_data = np.transpose(np.expand_dims(preprocess_input(np.array(image_data, np.float32)), 0), (0, 3, 1, 2))with torch.no_grad():photo = torch.from_numpy(image_data)if self.cuda:photo = photo.cuda()#---------------------------------------------------## 图片传入网络进行预测#---------------------------------------------------#preds = torch.softmax(self.model(photo)[0], dim=-1).cpu().numpy()#---------------------------------------------------## 获得所属种类#---------------------------------------------------#class_name = self.class_names[np.argmax(preds)]probability = np.max(preds)#---------------------------------------------------## 绘图并写字#---------------------------------------------------#plt.subplot(1, 1, 1)plt.imshow(np.array(image))plt.title('Class:%s Probability:%.3f' %(class_name, probability))plt.show()return class_name
3、直接运行predict.py ,无需修改任何参数
'''
predict.py有几个注意点
1、无法进行批量预测,如果想要批量预测,可以利用os.listdir()遍历文件夹,利用Image.open打开图片文件进行预测。
2、如果想要将预测结果保存成txt,可以利用open打开txt文件,使用write方法写入txt,可以参考一下txt_annotation.py文件。
'''
from PIL import Imagefrom classification import Classificationclassfication = Classification()while True:img = input('Input image filename:')try:image = Image.open(img)except:print('Open Error! Try again!')continueelse:class_name = classfication.detect_image(image)print(class_name)
4、看结果

准确率还可以,本人时间有限,目前数据集较少,接下来多做数据集效果更好!
Predict-利用训练好的网络进行预测_哔哩哔哩_bilibili
查看GPU运行情况(关于cuda的gpu查看方法、效果、安装等可以参考博文)
(1336条消息) 系统多cuda版本的自由切换_彩色海绵的博客-CSDN博客
(1336条消息) pytorch训练第一个项目VOC2007_彩色海绵的博客-CSDN博客
